# ES+Kibana+Logstash 部署
# 部署文件
先创建容器网络(也可以不创建,把 networks 相关的都删了,会自动创建)
docker network create elk |
一定要一次性弄完再 up, 不然会出现神奇的 bug。。。
version: "2" | |
services: | |
elasticsearch: | |
image: elasticsearch:7.13.1 | |
container_name: elasticsearch | |
volumes: | |
- "./elasticsearch_data:/bitnami/elasticsearch" | |
ports: | |
- "9200:9200" | |
- "9300:9300" | |
environment: | |
- TZ=Asia/Shanghai | |
- discovery.type=single-node | |
- "ES_JAVA_OPTS=-Xms512m -Xmx512m" | |
privileged: true | |
ulimits: | |
nofile: | |
soft: 65536 | |
hard: 65536 | |
networks: | |
- elk | |
kibana: | |
image: kibana:7.13.1 | |
container_name: kibana | |
environment: | |
- elasticsearch.hosts=http://elasticsearch:9200 | |
- TZ=Asia/Shanghai | |
restart: always | |
ports: | |
- "5601:5601" | |
volumes: | |
- "./kibana_data:/bitnami/kibana" | |
depends_on: | |
- elasticsearch | |
networks: | |
- elk | |
logstash: | |
image: docker.elastic.co/logstash/logstash:7.13.1 | |
container_name: logstash | |
volumes: | |
- "./logstash.conf:/usr/share/logstash/pipeline/logstash.conf" | |
- "/home/elk/log.log:/home/elk/log.log" | |
environment: | |
- "XPACK_MONITORING_ENABLED=false" | |
- TZ=Asia/Shanghai | |
depends_on: | |
- elasticsearch | |
networks: | |
- elk | |
networks: | |
elk: | |
external: true |
- 将要挂载的宿主机目录设置为最高权限
chmod 777 目录名 |
# 重要说明
elasticsearch和kibana的宿主机挂载目录都是任意指定的,建议使用一个路径而不是匿名卷(否则重启容器可能出现各种 bug)container_name字段不可省略,否则kibana和logstash可能会找不到elasticsearch,因为自动创建的容器名称自带前缀logstash的volumes字段里,第一个用于指定logstash.conf的位置,第二个用于确定日志搜集路径
(可以先部署前两个,搞定了再把第三个加进来,结合后面的 logstash 说明)
# 验证
- 访问
http://localhost:9200
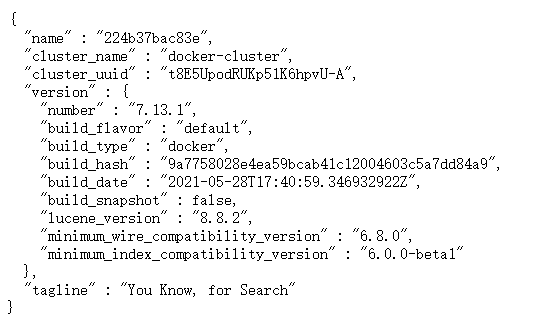
- 访问
http://localhost:5601

验证部署成功
# 什么是 Elasticsearch?
Elasticsearch is a real-time, distributed storage, search, and analytics engine.
Elasticsearch 是一个实时的分布式存储、搜索、分析的引擎。
相对于数据库,Elasticsearch 的强大之处就是可以模糊查询。
数据库的模糊查询:
select * from user where name like '%something%' |
但这样是不通过索引查询的,意味着:只要数据库的量很大(1 亿条),查询肯定会是秒级别的。
而且,即便给你从数据库根据模糊匹配查出相应的记录了,那往往会返回大量的数据给你,往往你需要的数据量并没有这么多,可能 50 条记录就足够了。
还有一个就是:用户输入的内容往往并没有这么的精确,比如我从 Google 输入 ElastcSeach (打错字),但是 Google 还是能估算我想输入的是 Elasticsearch
而 Elasticsearch 是专门做搜索的,就是为了解决上面所讲的问题而生的,换句话说:
- Elasticsearch 对模糊搜索非常擅长(搜索速度很快)
- 从 Elasticsearch 搜索到的数据可以根据评分过滤掉大部分的,只要返回评分高的给用户就好了(原生就支持排序)
- 没有那么准确的关键字也能搜出相关的结果(能匹配有相关性的记录)
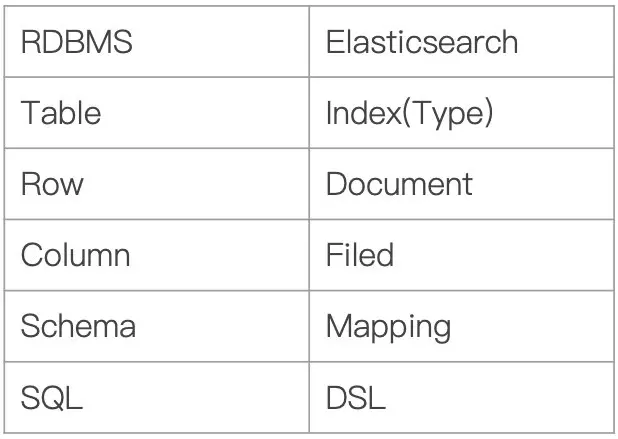
# Elasticsearch 的术语和架构
Index:Elasticsearch 的 Index 相当于数据库的 Table
Type:这个在新的 Elasticsearch 版本已经废除(在以前的 Elasticsearch 版本,一个 Index 下支持多个 Type–有点类似于消息队列一个 topic 下多个 group 的概念)
Document:Document 相当于数据库的一行记录
Field:相当于数据库的 Column 的概念
Mapping:相当于数据库的 Schema 的概念
DSL:相当于数据库的 SQL(给我们读取 Elasticsearch 数据的 API)
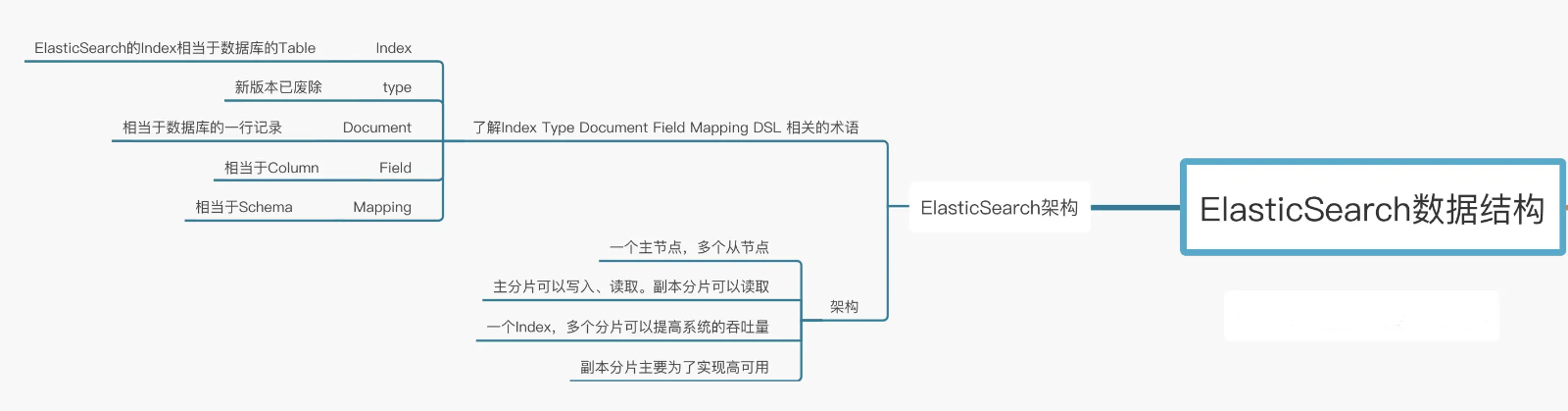
一个 Elasticsearch 集群会有多个 Elasticsearch 节点,所谓节点实际上就是运行着 Elasticsearch 进程的机器。
在众多的节点中,其中会有一个 Master Node ,它主要负责维护索引元数据、负责切换主分片和副本分片身份等工作(后面会讲到分片的概念),如果主节点挂了,会选举出一个新的主节点。
# 倒排索引
# 正排索引(传统)
| id | content |
|---|---|
| 1001 | my name is zhang san |
| 1002 | my name is li si |
# 倒排索引
| keyword | id |
|---|---|
| name | 1001,1002 |
| zhang | 1001 |
Elasticsearch 是面向文档型数据库,一条数据在这里就是一个文档。 为了方便大家理解,我们将 Elasticsearch 里存储文档数据和关系型数据库 MySQL 存储数据的概念进行一个类比:
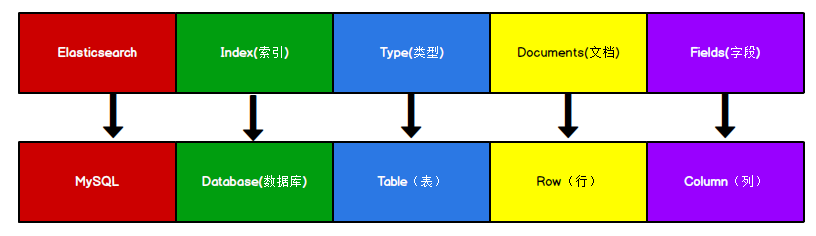
ES 里的 Index 可以看做一个库,而 Types 相当于表, Documents 则相当于表的行。这里 Types 的概念已经被逐渐弱化, Elasticsearch 6.X 中,一个 index 下已经只能包含一个 type, Elasticsearch7.X 中,Type 的概念已经被删除了。
# ES API
# 创建索引
curl -X PUT 192.168.10.100:9200/www |
输出:
{ | |
"acknowledged": true,// 响应结果 | |
"shards_acknowledged": true,// 分片结果 | |
"index": "www"// 索引名称 | |
} |
重复发送:
{ | |
"error": { | |
"root_cause": [ | |
{ | |
"type": "resource_already_exists_exception", | |
"reason": "index [shopping/J0WlEhh4R7aDrfIc3AkwWQ] already exists", | |
"index_uuid": "J0WlEhh4R7aDrfIc3AkwWQ", | |
"index": "shopping" | |
} | |
], | |
"type": "resource_already_exists_exception", | |
"reason": "index [shopping/J0WlEhh4R7aDrfIc3AkwWQ] already exists", | |
"index_uuid": "J0WlEhh4R7aDrfIc3AkwWQ", | |
"index": "shopping" | |
}, | |
"status": 400 | |
} |
# 查看健康状态
curl -X GET 192.168.10.100:9200/_cat/health?v |
# 查询所有索引
curl -X GET 192.168.10.100:9200/_cat/indices?v |
这里请求路径中的_cat 表示查看的意思, indices 表示索引,所以整体含义就是查看当前 ES 服务器中的所有索引,就好像 MySQL 中的 show tables 的感觉,服务器响应结果如下 :
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size | |
green open .kibana_task_manager_7.13.1_001 Jp6kivOgSlS3msJfLPptaA 1 0 10 3 119.6kb 119.6kb | |
green open .apm-custom-link lZ8SB-tfT-CZfY6g9aVePA 1 0 0 0 208b 208b | |
yellow open fund kVUWo0J8SEqPe7M4qWBalQ 1 1 0 0 208b 208b | |
yellow open www YcZKzL2hRDiI0RVtdTLj0w 1 1 0 0 208b 208b | |
green open .apm-agent-configuration YBy232SXQKCCBqdPHZhFKw 1 0 0 0 208b 208b | |
green open .kibana-event-log-7.13.1-000001 WfHlPuubRJytriWq8ld3mA 1 0 1 0 5.6kb 5.6kb | |
green open .kibana_7.13.1_001 Ox-zOiolQ-Wc0StQe9G89A 1 0 10 1 2.1mb 2.1mb |
| 表头 | 含义 |
|---|---|
| health | 当前服务器健康状态:green (集群完整) yellow (单点正常、集群不完整) red (单点不正常) |
| status | 索引打开、关闭状态 |
| index | 索引统一编号 |
| pri | 主分片数量 |
| rep | 副本数量 |
| docs.count | 可用文档数量 |
| docs.deleted | 文档删除状态(逻辑删除) |
| store.size | 主分片和副分片整体占空间大小 |
| pri.store.size | 主分片占空间大小 |
# 查看单个索引
curl -X GET 192.168.10.100:9200/www |
返回结果如下:
{ | |
"shopping": {// 索引名 | |
"aliases": {},// 别名 | |
"mappings": {},// 映射 | |
"settings": {// 设置 | |
"index": {// 设置 - 索引 | |
"creation_date": "1617861426847",// 设置 - 索引 - 创建时间 | |
"number_of_shards": "1",// 设置 - 索引 - 主分片数量 | |
"number_of_replicas": "1",// 设置 - 索引 - 主分片数量 | |
"uuid": "J0WlEhh4R7aDrfIc3AkwWQ",// 设置 - 索引 - 主分片数量 | |
"version": {// 设置 - 索引 - 主分片数量 | |
"created": "7080099" | |
}, | |
"provided_name": "shopping"// 设置 - 索引 - 主分片数量 | |
} | |
} | |
} | |
} |
# 创建文档
假设索引已经创建好了,接下来我们来创建文档,并添加数据。这里的文档可以类比为关系型数据库中的表数据,添加的数据格式为 JSON 格式
在 Postman 中,向 ES 服务器发 POST 请求 : http://192.168.10.100:9200/shopping/_doc ,请求体 JSON 内容为:
{ | |
"title":"小米手机", | |
"category":"小米", | |
"images":"http://www.gulixueyuan.com/xm.jpg", | |
"price":3999.00 | |
} |
注意,此处发送请求的方式必须为 POST,不能是 PUT,否则会发生错误 。
{ | |
"_index": "shopping",// 索引 | |
"_type": "_doc",// 类型 - 文档 | |
"_id": "ANQqsHgBaKNfVnMbhZYU",// 唯一标识,可以类比为 MySQL 中的主键,随机生成 | |
"_version": 1,// 版本 | |
"result": "created",// 结果,这里的 create 表示创建成功 | |
"_shards": {// | |
"total": 2,// 分片 - 总数 | |
"successful": 1,// 分片 - 总数 | |
"failed": 0// 分片 - 总数 | |
}, | |
"_seq_no": 0, | |
"_primary_term": 1 | |
} |
上面的数据创建后,由于没有指定数据唯一性标识(ID),默认情况下, ES 服务器会随机生成一个。
如果想要自定义唯一性标识,需要在创建时指定: http://192.168.10.100:9200/shopping/_doc/1 ,请求体 JSON 内容为:
{ | |
"title":"小米手机", | |
"category":"小米", | |
"images":"http://www.gulixueyuan.com/xm.jpg", | |
"price":3999.00 | |
} |
返回结果如下:
{ | |
"_index": "shopping", | |
"_type": "_doc", | |
"_id": "1",//<------------------ 自定义唯一性标识 | |
"_version": 1, | |
"result": "created", | |
"_shards": { | |
"total": 2, | |
"successful": 1, | |
"failed": 0 | |
}, | |
"_seq_no": 1, | |
"_primary_term": 1 | |
} |
此处需要注意:如果增加数据时明确数据主键,那么请求方式也可以为 PUT。
# 查询文档
# 主键查询
查看文档时,需要指明文档的唯一性标识,类似于 MySQL 中数据的主键查询
在 Postman 中,向 ES 服务器发 GET 请求 : http://192.168.10.100:9200/shopping/_doc/1 返回结果如下:
返回结果如下:
{ | |
"_index": "shopping", | |
"_type": "_doc", | |
"_id": "1", | |
"_version": 1, | |
"_seq_no": 1, | |
"_primary_term": 1, | |
"found": true, | |
"_source": { | |
"title": "小米手机", | |
"category": "小米", | |
"images": "http://www.gulixueyuan.com/xm.jpg", | |
"price": 3999 | |
} | |
} |
查找不存在的内容,向 ES 服务器发 GET 请求 : http://192.168.10.100:9200/shopping/_doc/1001
返回结果如下:
{ | |
"_index": "shopping", | |
"_type": "_doc", | |
"_id": "1001", | |
"found": false | |
} |
# 全查询
查看索引下所有数据,向 ES 服务器发 GET 请求 : http://192.168.10.100:9200/shopping/_search
返回结果如下:
{ | |
"took": 133, | |
"timed_out": false, | |
"_shards": { | |
"total": 1, | |
"successful": 1, | |
"skipped": 0, | |
"failed": 0 | |
}, | |
"hits": { | |
"total": { | |
"value": 2, | |
"relation": "eq" | |
}, | |
"max_score": 1, | |
"hits": [ | |
{ | |
"_index": "shopping", | |
"_type": "_doc", | |
"_id": "ANQqsHgBaKNfVnMbhZYU", | |
"_score": 1, | |
"_source": { | |
"title": "小米手机", | |
"category": "小米", | |
"images": "http://www.gulixueyuan.com/xm.jpg", | |
"price": 3999 | |
} | |
}, | |
{ | |
"_index": "shopping", | |
"_type": "_doc", | |
"_id": "1", | |
"_score": 1, | |
"_source": { | |
"title": "小米手机", | |
"category": "小米", | |
"images": "http://www.gulixueyuan.com/xm.jpg", | |
"price": 3999 | |
} | |
} | |
] | |
} | |
} |
# 修改文档
# 全量修改
和新增文档一样,输入相同的 URL 地址请求,如果请求体变化,会将原有的数据内容覆盖
在 Postman 中,向 ES 服务器发 POST 请求 : http://192.168.10.100:9200/shopping/_doc/1
请求体 JSON 内容为:
{ | |
"title":"华为手机", | |
"category":"华为", | |
"images":"http://www.gulixueyuan.com/hw.jpg", | |
"price":1999.00 | |
} |
修改成功后,服务器响应结果:
{ | |
"_index": "shopping", | |
"_type": "_doc", | |
"_id": "1", | |
"_version": 2, | |
"result": "updated",//<-----------updated 表示数据被更新 | |
"_shards": { | |
"total": 2, | |
"successful": 1, | |
"failed": 0 | |
}, | |
"_seq_no": 2, | |
"_primary_term": 1 | |
} |
# 局部修改
修改数据时,也可以只修改某一给条数据的局部信息
在 Postman 中,向 ES 服务器发 POST 请求 : http://192.168.10.100:9200/shopping/_update/1
请求体 JSON 内容为:
{ | |
"doc": { | |
"title":"小米手机", | |
"category":"小米" | |
} | |
} |
返回结果如下:
{ | |
"_index": "shopping", | |
"_type": "_doc", | |
"_id": "1", | |
"_version": 3, | |
"result": "updated",//<-----------updated 表示数据被更新 | |
"_shards": { | |
"total": 2, | |
"successful": 1, | |
"failed": 0 | |
}, | |
"_seq_no": 3, | |
"_primary_term": 1 | |
} |
# 删除文档
删除一个文档不会立即从磁盘上移除,它只是被标记成已删除(逻辑删除)。
在 Postman 中,向 ES 服务器发 DELETE 请求 : http://192.168.10.100:9200/shopping/_doc/1
返回结果:
{ | |
"_index": "shopping", | |
"_type": "_doc", | |
"_id": "1", | |
"_version": 4, | |
"result": "deleted",//<--- 删除成功 | |
"_shards": { | |
"total": 2, | |
"successful": 1, | |
"failed": 0 | |
}, | |
"_seq_no": 4, | |
"_primary_term": 1 | |
} |
# 高级查询
# 条件查询
假设有以下文档内容:
{ | |
"took": 5, | |
"timed_out": false, | |
"_shards": { | |
"total": 1, | |
"successful": 1, | |
"skipped": 0, | |
"failed": 0 | |
}, | |
"hits": { | |
"total": { | |
"value": 6, | |
"relation": "eq" | |
}, | |
"max_score": 1, | |
"hits": [ | |
{ | |
"_index": "shopping", | |
"_type": "_doc", | |
"_id": "ANQqsHgBaKNfVnMbhZYU", | |
"_score": 1, | |
"_source": { | |
"title": "小米手机", | |
"category": "小米", | |
"images": "http://www.gulixueyuan.com/xm.jpg", | |
"price": 3999 | |
} | |
}, | |
{ | |
"_index": "shopping", | |
"_type": "_doc", | |
"_id": "A9R5sHgBaKNfVnMb25Ya", | |
"_score": 1, | |
"_source": { | |
"title": "小米手机", | |
"category": "小米", | |
"images": "http://www.gulixueyuan.com/xm.jpg", | |
"price": 1999 | |
} | |
}, | |
{ | |
"_index": "shopping", | |
"_type": "_doc", | |
"_id": "BNR5sHgBaKNfVnMb7pal", | |
"_score": 1, | |
"_source": { | |
"title": "小米手机", | |
"category": "小米", | |
"images": "http://www.gulixueyuan.com/xm.jpg", | |
"price": 1999 | |
} | |
}, | |
{ | |
"_index": "shopping", | |
"_type": "_doc", | |
"_id": "BtR6sHgBaKNfVnMbX5Y5", | |
"_score": 1, | |
"_source": { | |
"title": "华为手机", | |
"category": "华为", | |
"images": "http://www.gulixueyuan.com/xm.jpg", | |
"price": 1999 | |
} | |
}, | |
{ | |
"_index": "shopping", | |
"_type": "_doc", | |
"_id": "B9R6sHgBaKNfVnMbZpZ6", | |
"_score": 1, | |
"_source": { | |
"title": "华为手机", | |
"category": "华为", | |
"images": "http://www.gulixueyuan.com/xm.jpg", | |
"price": 1999 | |
} | |
}, | |
{ | |
"_index": "shopping", | |
"_type": "_doc", | |
"_id": "CdR7sHgBaKNfVnMbsJb9", | |
"_score": 1, | |
"_source": { | |
"title": "华为手机", | |
"category": "华为", | |
"images": "http://www.gulixueyuan.com/xm.jpg", | |
"price": 1999 | |
} | |
} | |
] | |
} | |
} |
# 请求体带参查询
查找 category 为小米的文档,在 Postman 中,向 ES 服务器发 GET 请求 : http://192.168.10.100:9200/shopping/_search ,附带 JSON 体如下:
{ | |
"query":{ | |
"match":{ | |
"category":"小米" | |
} | |
} | |
} |
返回结果如下:
{ | |
"took": 3, | |
"timed_out": false, | |
"_shards": { | |
"total": 1, | |
"successful": 1, | |
"skipped": 0, | |
"failed": 0 | |
}, | |
"hits": { | |
"total": { | |
"value": 3, | |
"relation": "eq" | |
}, | |
"max_score": 1.3862942, | |
"hits": [ | |
{ | |
"_index": "shopping", | |
"_type": "_doc", | |
"_id": "ANQqsHgBaKNfVnMbhZYU", | |
"_score": 1.3862942, | |
"_source": { | |
"title": "小米手机", | |
"category": "小米", | |
"images": "http://www.gulixueyuan.com/xm.jpg", | |
"price": 3999 | |
} | |
}, | |
{ | |
"_index": "shopping", | |
"_type": "_doc", | |
"_id": "A9R5sHgBaKNfVnMb25Ya", | |
"_score": 1.3862942, | |
"_source": { | |
"title": "小米手机", | |
"category": "小米", | |
"images": "http://www.gulixueyuan.com/xm.jpg", | |
"price": 1999 | |
} | |
}, | |
{ | |
"_index": "shopping", | |
"_type": "_doc", | |
"_id": "BNR5sHgBaKNfVnMb7pal", | |
"_score": 1.3862942, | |
"_source": { | |
"title": "小米手机", | |
"category": "小米", | |
"images": "http://www.gulixueyuan.com/xm.jpg", | |
"price": 1999 | |
} | |
} | |
] | |
} | |
} |
# 查找所有文档内容
在 Postman 中,向 ES 服务器发 GET 请求: http://192.168.10.100:9200/shopping/_search ,附带 JSON 体如下:
{ | |
"query":{ | |
"match_all":{} | |
} | |
} |
则返回所有文档内容。
# 查询指定字段
在 Postman 中,向 ES 服务器发 GET 请求 : http://192.168.10.100:9200/shopping/_search ,附带 JSON 体如下:
{ | |
"query":{ | |
"match_all":{} | |
}, | |
"_source":["title"] | |
} |
# 分页查询
{ | |
"query":{ | |
"match_all":{} | |
}, | |
"from":0, | |
"size":2 | |
} |
# 查询排序
{ | |
"query":{ | |
"match_all":{} | |
}, | |
"sort":{ | |
"price":{ | |
"order":"desc" | |
} | |
} | |
} |
# 多条件查询
假设想找出小米牌子,价格为 3999 元的。(must 相当于数据库的 &&)
在 Postman 中,向 ES 服务器发 GET 请求 : http://192.168.10.100:9200/shopping/_search ,附带 JSON 体如下:
{ | |
"query":{ | |
"bool":{ | |
"must":[{ | |
"match":{ | |
"category":"小米" | |
} | |
},{ | |
"match":{ | |
"price":3999.00 | |
} | |
}] | |
} | |
} | |
} |
假设想找出小米和华为的牌子。(should 相当于数据库的 ||)
在 Postman 中,向 ES 服务器发 GET 请求 : http://192.168.10.100:9200/shopping/_search ,附带 JSON 体如下:
{ | |
"query":{ | |
"bool":{ | |
"should":[{ | |
"match":{ | |
"category":"小米" | |
} | |
},{ | |
"match":{ | |
"category":"华为" | |
} | |
}] | |
}, | |
"filter":{ | |
"range":{ | |
"price":{ | |
"gt":2000 | |
} | |
} | |
} | |
} | |
} |
# 范围查询
假设想找出小米和华为的牌子,价格大于 2000 元的手机。
在 Postman 中,向 ES 服务器发 GET 请求 : http://192.168.10.100:9200/shopping/_search ,附带 JSON 体如下:
{ | |
"query":{ | |
"bool":{ | |
"should":[{ | |
"match":{ | |
"category":"小米" | |
} | |
},{ | |
"match":{ | |
"category":"华为" | |
} | |
}], | |
"filter":{ | |
"range":{ | |
"price":{ | |
"gt":2000 | |
} | |
} | |
} | |
} | |
} | |
} |
# 全文检索
这功能像搜索引擎那样,如品牌输入 “小华”,返回结果带回品牌有 “小米” 和” 华为” 的。
在 Postman 中,向 ES 服务器发 GET 请求 : http://192.168.10.100:9200/shopping/_search ,附带 JSON 体如下:
{ | |
"query":{ | |
"match":{ | |
"category" : "小华" | |
} | |
} | |
} |
# 完全匹配
在 Postman 中,向 ES 服务器发 GET 请求 : http://192.168.10.100:9200/shopping/_search ,附带 JSON 体如下:
{ | |
"query":{ | |
"match_phrase":{ | |
"category" : "为" | |
} | |
} | |
} |
# 高亮查询
在 Postman 中,向 ES 服务器发 GET 请求 : http://192.168.10.100:9200/shopping/_search ,附带 JSON 体如下:
{ | |
"query":{ | |
"match_phrase":{ | |
"category" : "为" | |
} | |
}, | |
"highlight":{ | |
"fields":{ | |
"category":{}//<---- 高亮这字段 | |
} | |
} | |
} |
返回结果如下:
{ | |
"took": 100, | |
"timed_out": false, | |
"_shards": { | |
"total": 1, | |
"successful": 1, | |
"skipped": 0, | |
"failed": 0 | |
}, | |
"hits": { | |
"total": { | |
"value": 3, | |
"relation": "eq" | |
}, | |
"max_score": 0.6931471, | |
"hits": [ | |
{ | |
"_index": "shopping", | |
"_type": "_doc", | |
"_id": "BtR6sHgBaKNfVnMbX5Y5", | |
"_score": 0.6931471, | |
"_source": { | |
"title": "华为手机", | |
"category": "华为", | |
"images": "http://www.gulixueyuan.com/xm.jpg", | |
"price": 1999 | |
}, | |
"highlight": { | |
"category": [ | |
"华<em>为</em>"//<------ 高亮一个为字。 | |
] | |
} | |
}, | |
{ | |
"_index": "shopping", | |
"_type": "_doc", | |
"_id": "B9R6sHgBaKNfVnMbZpZ6", | |
"_score": 0.6931471, | |
"_source": { | |
"title": "华为手机", | |
"category": "华为", | |
"images": "http://www.gulixueyuan.com/xm.jpg", | |
"price": 1999 | |
}, | |
"highlight": { | |
"category": [ | |
"华<em>为</em>" | |
] | |
} | |
}, | |
{ | |
"_index": "shopping", | |
"_type": "_doc", | |
"_id": "CdR7sHgBaKNfVnMbsJb9", | |
"_score": 0.6931471, | |
"_source": { | |
"title": "华为手机", | |
"category": "华为", | |
"images": "http://www.gulixueyuan.com/xm.jpg", | |
"price": 1999 | |
}, | |
"highlight": { | |
"category": [ | |
"华<em>为</em>" | |
] | |
} | |
} | |
] | |
} | |
} |
# 聚合查询
# 带原始数据
聚合允许使用者对 es 文档进行统计分析,类似与关系型数据库中的 group by,当然还有很多其他的聚合,例如取最大值 max、平均值 avg 等等。
接下来按 price 字段进行分组:
在 Postman 中,向 ES 服务器发 GET 请求 : http://192.168.10.100:9200/shopping/_search ,附带 JSON 体如下:
{ | |
"aggs":{// 聚合操作 | |
"price_group":{// 名称,随意起名 | |
"terms":{// 分组 | |
"field":"price"// 分组字段 | |
} | |
} | |
} | |
} |
返回结果如下:
{ | |
"took": 63, | |
"timed_out": false, | |
"_shards": { | |
"total": 1, | |
"successful": 1, | |
"skipped": 0, | |
"failed": 0 | |
}, | |
"hits": { | |
"total": { | |
"value": 6, | |
"relation": "eq" | |
}, | |
"max_score": 1, | |
"hits": [ | |
{ | |
"_index": "shopping", | |
"_type": "_doc", | |
"_id": "ANQqsHgBaKNfVnMbhZYU", | |
"_score": 1, | |
"_source": { | |
"title": "小米手机", | |
"category": "小米", | |
"images": "http://www.gulixueyuan.com/xm.jpg", | |
"price": 3999 | |
} | |
}, | |
{ | |
"_index": "shopping", | |
"_type": "_doc", | |
"_id": "A9R5sHgBaKNfVnMb25Ya", | |
"_score": 1, | |
"_source": { | |
"title": "小米手机", | |
"category": "小米", | |
"images": "http://www.gulixueyuan.com/xm.jpg", | |
"price": 1999 | |
} | |
}, | |
{ | |
"_index": "shopping", | |
"_type": "_doc", | |
"_id": "BNR5sHgBaKNfVnMb7pal", | |
"_score": 1, | |
"_source": { | |
"title": "小米手机", | |
"category": "小米", | |
"images": "http://www.gulixueyuan.com/xm.jpg", | |
"price": 1999 | |
} | |
}, | |
{ | |
"_index": "shopping", | |
"_type": "_doc", | |
"_id": "BtR6sHgBaKNfVnMbX5Y5", | |
"_score": 1, | |
"_source": { | |
"title": "华为手机", | |
"category": "华为", | |
"images": "http://www.gulixueyuan.com/xm.jpg", | |
"price": 1999 | |
} | |
}, | |
{ | |
"_index": "shopping", | |
"_type": "_doc", | |
"_id": "B9R6sHgBaKNfVnMbZpZ6", | |
"_score": 1, | |
"_source": { | |
"title": "华为手机", | |
"category": "华为", | |
"images": "http://www.gulixueyuan.com/xm.jpg", | |
"price": 1999 | |
} | |
}, | |
{ | |
"_index": "shopping", | |
"_type": "_doc", | |
"_id": "CdR7sHgBaKNfVnMbsJb9", | |
"_score": 1, | |
"_source": { | |
"title": "华为手机", | |
"category": "华为", | |
"images": "http://www.gulixueyuan.com/xm.jpg", | |
"price": 1999 | |
} | |
} | |
] | |
}, | |
"aggregations": { | |
"price_group": { | |
"doc_count_error_upper_bound": 0, | |
"sum_other_doc_count": 0, | |
"buckets": [ | |
{ | |
"key": 1999, | |
"doc_count": 5 | |
}, | |
{ | |
"key": 3999, | |
"doc_count": 1 | |
} | |
] | |
} | |
} | |
} |
# 不带原始数据
在 Postman 中,向 ES 服务器发 GET 请求 : http://192.168.10.100:9200/shopping/_search ,附带 JSON 体如下:
{ | |
"aggs":{ | |
"price_group":{ | |
"terms":{ | |
"field":"price" | |
} | |
} | |
}, | |
"size":0 | |
} |
返回结果如下:
{ | |
"took": 60, | |
"timed_out": false, | |
"_shards": { | |
"total": 1, | |
"successful": 1, | |
"skipped": 0, | |
"failed": 0 | |
}, | |
"hits": { | |
"total": { | |
"value": 6, | |
"relation": "eq" | |
}, | |
"max_score": null, | |
"hits": [] | |
}, | |
"aggregations": { | |
"price_group": { | |
"doc_count_error_upper_bound": 0, | |
"sum_other_doc_count": 0, | |
"buckets": [ | |
{ | |
"key": 1999, | |
"doc_count": 5 | |
}, | |
{ | |
"key": 3999, | |
"doc_count": 1 | |
} | |
] | |
} | |
} | |
} |
# 平均值
{ | |
"aggs":{ | |
"price_avg":{// 名称,随意起名 | |
"avg":{// 求平均 | |
"field":"price" | |
} | |
} | |
}, | |
"size":0 | |
} |
# 映射关系
创建数据库表需要设置字段名称,类型,长度,约束等;索引库也一样,需要知道这个类型下有哪些字段,每个字段有哪些约束信息,这就叫做映射 (mapping)。
先创建一个索引:
PUT http://192.168.10.100:9200/user |
# 创建映射
# PUT http://127.0.0.1:9200/user/_mapping | |
{ | |
"properties": { | |
"name":{ | |
"type": "text", | |
"index": true | |
}, | |
"sex":{ | |
"type": "keyword", | |
"index": true | |
}, | |
"tel":{ | |
"type": "keyword", | |
"index": false | |
} | |
} | |
} |
# 查询映射
GET http://127.0.0.1:9200/user/_mapping |
返回结果如下:
{ | |
"user": { | |
"mappings": { | |
"properties": { | |
"name": { | |
"type": "text" | |
}, | |
"sex": { | |
"type": "keyword" | |
}, | |
"tel": { | |
"type": "keyword", | |
"index": false | |
} | |
} | |
} | |
} | |
} |
增加数据:
PUT http://127.0.0.1:9200/user/_create/1001 | |
{ | |
"name":"小米", | |
"sex":"男的", | |
"tel":"1111" | |
} |
设置为 keyword 的只能完全匹配
GET http://127.0.0.1:9200/user/_search | |
{ | |
"query":{ | |
"match":{ | |
"sex":"男" | |
} | |
} | |
} |
返回结果如下:
{ | |
"took": 1, | |
"timed_out": false, | |
"_shards": { | |
"total": 1, | |
"successful": 1, | |
"skipped": 0, | |
"failed": 0 | |
}, | |
"hits": { | |
"total": { | |
"value": 0, | |
"relation": "eq" | |
}, | |
"max_score": null, | |
"hits": [] | |
} | |
} |
index 设置为 false 查询不到
# 动态映射
Elasticsearch 具有一项称为 “动态映射”(Dynamic Mapping)的功能,它允许在插入文档时自动创建映射,而无需预先定义映射。这意味着您可以向索引中插入文档,Elasticsearch 会根据文档的结构自动创建相应的映射。这对于快速开始和灵活的数据处理非常有用。
# 删除索引
curl -X DELETE 192.168.10.100:9200/www |
输出:
{ | |
"acknowledged":true | |
} |
# Kibana
# Logstash
# 实践
创建一个 logstash.conf
input { | |
file { | |
path => "/home/elk/log.log" # 日志目录 | |
start_position => "beginning" # 从开头开始采集数据 | |
sincedb_path => "/dev/null" # 每次重新启动 Logstash 时,它都会从文件的开头开始读取数据。 | |
} | |
} | |
filter { | |
# grok 插件,匹配规则 | |
grok { | |
match => { "message" => "%{TIMESTAMP_ISO8601:timestamp} %{LOGLEVEL:loglevel} %{GREEDYDATA:msg}" } | |
} | |
mutate { | |
# 删除不想要的字段,某些固定字段无法删除 | |
remove_field => ["message","path","@version","host"] | |
} | |
} | |
output { | |
elasticsearch { | |
hosts => ["elasticsearch:9200"] # es 主机地址 | |
index => "log" # 需要发送的索引,无需提前创建 index 和 mapping | |
} | |
} |
然后把这个文件挂载到容器里,在 logstash 的 volumes 字段里加入,宿主机目录可以自定义。
- "./logstash.conf:/usr/share/logstash/pipeline/logstash.conf" |
随便创建一个目录用于存储目录文件
mkdir -p /home/elk/log.log |
vim 写一点内容
2023-08-20 15:30:45 INFO This is an informational log message. | |
2023-08-20 15:31:12 ERROR An error occurred in the application. | |
2023-08-20 15:32:05 WARNING This is a warning message. | |
2023-08-20 15:33:20 INFO Another informational log entry. | |
2023-08-20 15:34:05 DEBUG Debugging information for troubleshooting. | |
2023-08-20 15:30:45 INFO This is an informational log message. | |
2023-08-20 15:31:12 ERROR An error occurred in the application. | |
2023-08-20 15:32:05 WARNING This is a warning message. | |
2023-08-20 15:33:20 INFO Another informational log entry. | |
2023-08-20 15:34:05 DEBUG Debugging information for troubleshooting. |
Discover 里查看一下
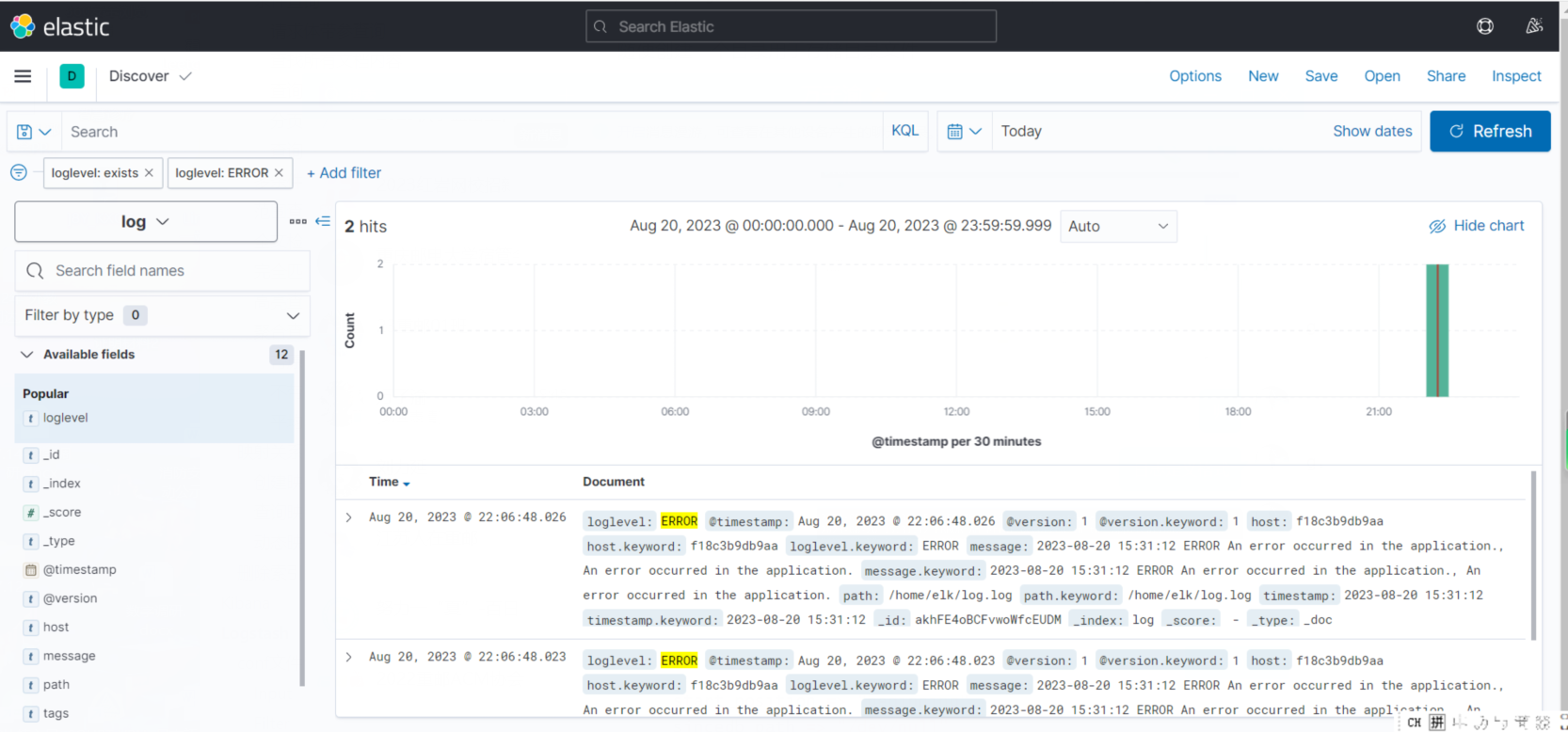
logstash.conf 使用了 ruby 语言,如果不会的话,我们就对 chatgpt 提需求吧!
input { | |
file { | |
path => "/home/project/GoYin/api/tmp/klog/logs/*.log" | |
start_position => "beginning" | |
sincedb_path => "/dev/null" | |
codec => "json" # 如果日志是 JSON 格式的 | |
tags => ["klog"] # 为这个输入添加一个标签以区分日志类型 | |
} | |
file { | |
path => "/home/project/GoYin/api/tmp/hlog/logs/*.log" | |
start_position => "beginning" | |
sincedb_path => "/dev/null" | |
codec => "json" # 如果您的日志是 JSON 格式的 | |
tags => ["hlog"] # 为这个输入添加一个标签以区分日志类型 | |
} | |
} | |
filter { | |
if "klog" in [tags] { | |
# 对于以 "klog" 标签标记的日志,您可以在这里进行特定的过滤和处理 | |
} else if "hlog" in [tags] { | |
# 对于以 "hlog" 标签标记的日志,您可以在这里进行特定的过滤和处理 | |
} | |
} | |
output { | |
if "klog" in [tags] { | |
elasticsearch { | |
hosts => ["your_elasticsearch_host"] | |
index => "klog-%{+YYYY.MM.dd}" | |
} | |
} else if "hlog" in [tags] { | |
elasticsearch { | |
hosts => ["your_elasticsearch_host"] | |
index => "hlog-%{+YYYY.MM.dd}" | |
} | |
} | |
} | |
# %{+YYYY.MM.dd} 会自动赋予当前日期 |
# conf 文件说明
# Input
事件源可以是从 stdin 屏幕输入读取,可以从 file 指定的文件,也可以从 es,filebeat,kafka,redis 等读取
stdin 标准输入
file 从文件读取数据
syslog 通过网络将系统日志消息读取为事件
# Filter
# Output
# Mysql 数据库同步
用 docker-compose 快速部署 MySQL 数据库
version: '3' | |
services: | |
mysql: | |
image: mysql:latest | |
container_name: mysql | |
environment: | |
MYSQL_ROOT_PASSWORD: 224488 | |
MYSQL_DATABASE: herbal | |
ports: | |
- "13306:3306" | |
volumes: | |
- "./mysql_data:/var/lib/mysql" | |
- "./init.sql:/docker-entrypoint-initdb.d/init.sql" | |
networks: | |
- elk | |
# 和刚才的放在一个 yml 文件里 |
init.sql
USE herbal; | |
CREATE TABLE herbs ( | |
id INT AUTO_INCREMENT PRIMARY KEY, | |
name VARCHAR(255) NOT NULL, | |
botanical_name VARCHAR(255) | |
); | |
INSERT INTO herbs (name, botanical_name) VALUES | |
('Herb 1', 'Botanical 1'), | |
('Herb 2', 'Botanical 2'), | |
('Herb 3', 'Botanical 3'); |
下载 jar 包
wget -P jdbc_driver https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.26/mysql-connector-java-8.0.26.jar |
logstash 中加上 jar 包的挂载路径
logstash: | |
image: docker.elastic.co/logstash/logstash:7.13.1 | |
container_name: logstash | |
volumes: | |
- "./logstash.conf:/usr/share/logstash/pipeline/logstash.conf" | |
- "/home/elk/log.log:/log/log.log" | |
- "./jdbc_driver/mysql-connector-java-8.0.26.jar:/jdbc_driver/mysql-connector-java-8.0.26.jar" | |
environment: | |
- "XPACK_MONITORING_ENABLED=false" | |
- TZ=Asia/Shanghai | |
depends_on: | |
- elasticsearch | |
networks: | |
- elk |
修改 logstash.conf
input { | |
jdbc { | |
jdbc_connection_string => "jdbc:mysql://mysql:13306/herbal" # mysql 更换成你的 mysql 主机 ip | |
jdbc_user => "root" | |
jdbc_password => "224488" | |
jdbc_driver_library => "/jdbc_driver/mysql-connector-java-8.0.26.jar" # 容器内的路径 | |
jdbc_driver_class => "com.mysql.cj.jdbc.Driver" | |
statement => "SELECT * FROM herbs" | |
schedule => "* * * * *" | |
} | |
} | |
filter { | |
} | |
output { | |
elasticsearch { | |
hosts => ["elasticsearch:9200"] | |
index => "mysql_data" | |
} | |
} |
# Geo 使用策略
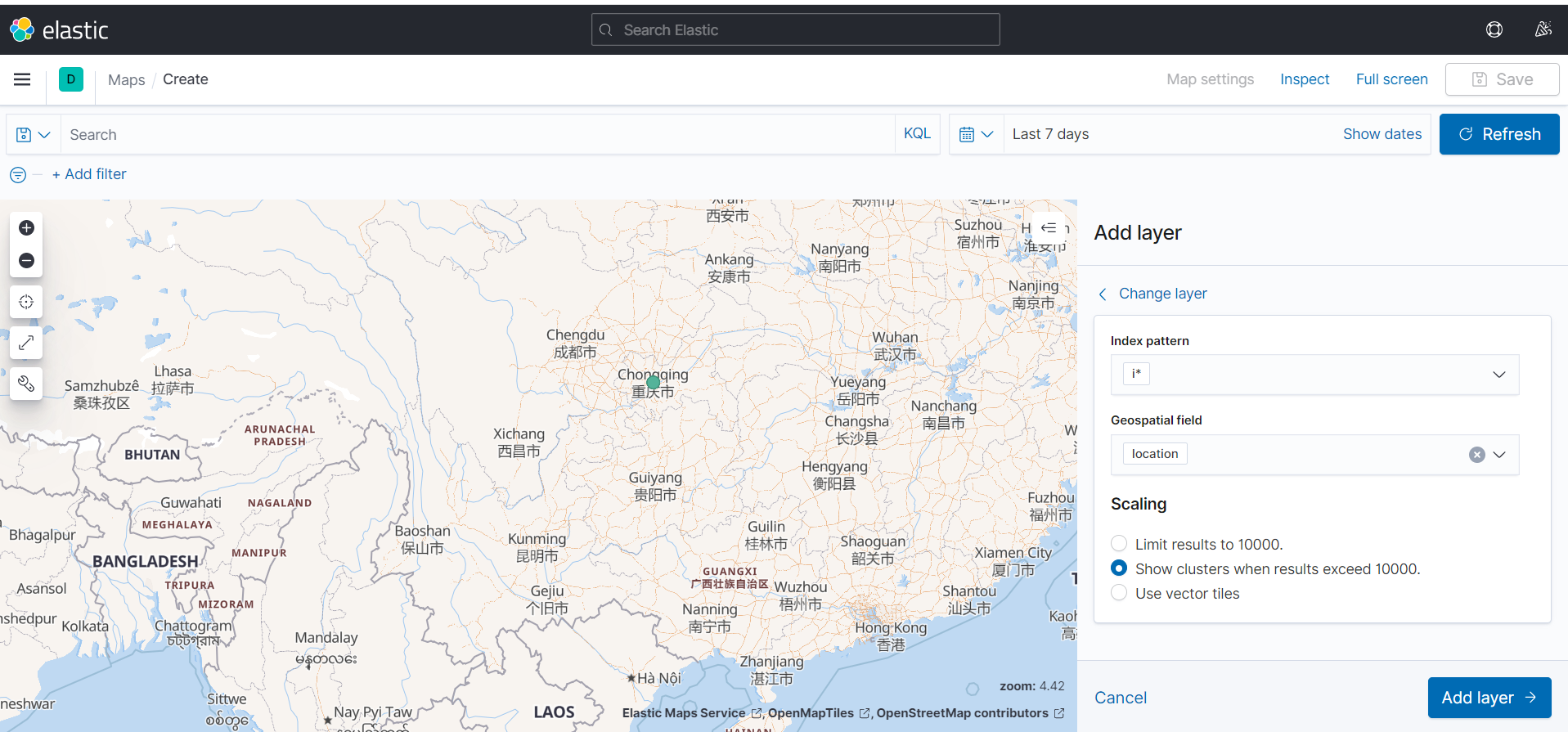
目前只实践成功一个方案,可以让 kibana 的 maps 识别到经纬度的数据,先把 logstash 关闭,1.2 步结束再关。
创建好要导入的索引
PUT http://{ip}:{port}/{your_index}
添加
location字段类型为geo_point(因为logstash自动搜集信息时不支持设置为此字段)// PUT http://{ip}:{port}/{your_index}/_mapping{"properties": {
"location": {
"type": "geo_point"
}}}logstash.conf的filter部分# 提前解析出来 "latitude" 和 "longitude" 字段mutate {convert => {
"latitude" => "float"
"longitude" => "float"
}}mutate {add_field => {
"location" => "%{[latitude]},%{[longitude]}"
}}kibana的maps可以自动选择location字段![1IEOK@V_9VRENT7DQ_@IJ`0.png]()
# 完整部署参考
version: "2" | |
services: | |
mysql: | |
image: mysql:5.7 | |
container_name: mysql | |
environment: | |
MYSQL_ROOT_PASSWORD: 224488 | |
MYSQL_DATABASE: herbal | |
ports: | |
- "13306:3306" | |
volumes: | |
- "./mysql_data:/var/lib/mysql" | |
- "./init.sql:/docker-entrypoint-initdb.d/init.sql" | |
networks: | |
- elk | |
elasticsearch: | |
image: elasticsearch:7.13.1 | |
container_name: elasticsearch | |
volumes: | |
- "./elasticsearch_data:/bitnami/elasticsearch" | |
ports: | |
- "9200:9200" | |
- "9300:9300" | |
environment: | |
- TZ=Asia/Shanghai | |
- discovery.type=single-node | |
- "ES_JAVA_OPTS=-Xms512m -Xmx512m" | |
privileged: true | |
ulimits: | |
nofile: | |
soft: 65536 | |
hard: 65536 | |
networks: | |
- elk | |
kibana: | |
image: kibana:7.13.1 | |
container_name: kibana | |
environment: | |
- elasticsearch.hosts=http://elasticsearch:9200 | |
- TZ=Asia/Shanghai | |
restart: always | |
ports: | |
- "5601:5601" | |
volumes: | |
- "./kibana_data:/bitnami/kibana" | |
depends_on: | |
- elasticsearch | |
networks: | |
- elk | |
logstash: | |
image: docker.elastic.co/logstash/logstash:7.13.1 | |
container_name: logstash | |
volumes: | |
- "./logstash.conf:/usr/share/logstash/pipeline/logstash.conf" | |
- "/home/elk/log/:/home/elk/log/" | |
- "./jdbc_driver/mysql-connector-java-8.0.26.jar:/jdbc_driver/mysql-connector-java-8.0.26.jar" | |
environment: | |
- "XPACK_MONITORING_ENABLED=false" | |
- TZ=Asia/Shanghai | |
depends_on: | |
- elasticsearch | |
networks: | |
- elk | |
phpmyadmin: | |
image: phpmyadmin:latest | |
container_name: phpadmin | |
ports: | |
- "3300:80" | |
environment: | |
PMA_ARBITRARY: 1 | |
PMA_HOST: mysql | |
PMA_USER: root | |
PMA_PASSWORD: 224488 | |
networks: | |
- elk | |
networks: | |
elk: | |
external: true |
# 参考链接
https://juejin.cn/post/6844904051994263559
https://www.liwenzhou.com/posts/Go/elasticsearch/
https://blog.csdn.net/u011863024/article/details/115721328
https://blog.csdn.net/JineD/article/details/114444239