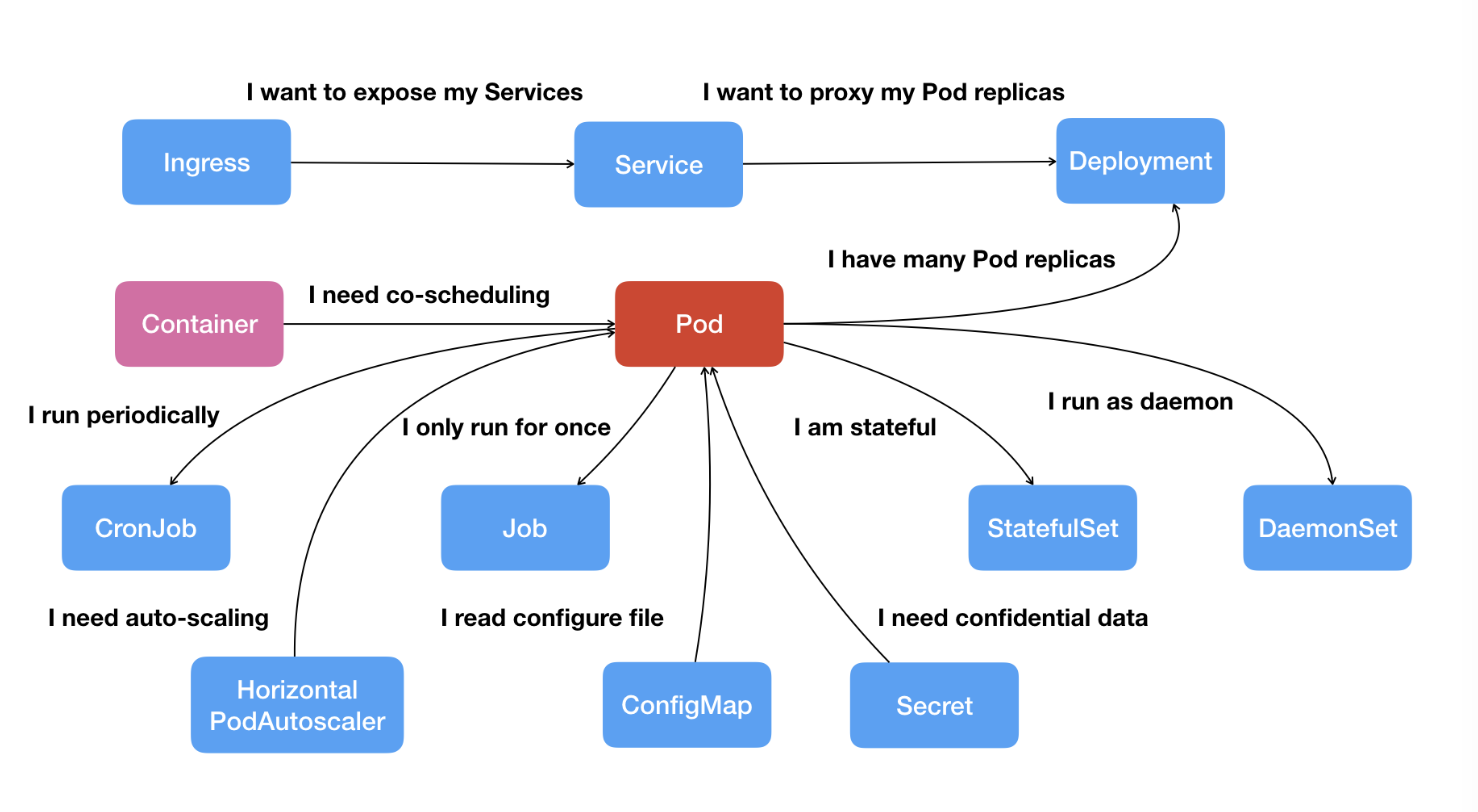
# Pod-"收纳仓"
- 从 Pod 开始,扩展出了 Kubernetes 里的一些重要 API 对象
apiVersion和kind这两个字段很简单,对于 Pod 来说分别是固定的值v1和Pod,而一般来说,“metadata” 里应该有name和labels这两个字段。但在 Kubernetes 里,Pod 必须要有一个名字。这也是 Kubernetes 里所有资源对象的一个约定。 一般加上
pod后缀name只是一个基本的标识,信息有限,所以labels字段就派上了用处。它可以添加任意数量的 Key-Value,给 Pod “贴” 上归类的标签,结合name就更方便识别和管理了。
根据运行环境, env=dev/test/prod
根据所在的数据中心,使用标签 region: north/south
根据应用在系统中的层次,使用 tier=front/middle/back
apiVersion: v1 | |
kind: Pod | |
metadata: | |
name: busy-pod | |
labels: | |
owner: chrono | |
env: demo | |
region: north | |
tier: back |
# container
“containers” 是一个数组,里面的每一个元素又是一个 container 对象,也就是容器。
- container 对象也必须要有一个
name表示名字,然后当然还要有一个image字段来说明它使用的镜像,这两个字段是必须要有的 。
# 字段
ports:列出容器对外暴露的端口,和 Docker 的
-p参数有点像。imagePullPolicy:指定镜像的拉取策略,可以是
Always/Never/IfNotPresent,一般默认是IfNotPresent,也就是说只有本地不存在才会远程拉取镜像,可以减少网络消耗。env:定义 Pod 的环境变量,和 Dockerfile 里的
ENV指令有点类似,但它是运行时指定的,更加灵活可配置。command:定义容器启动时要执行的命令,相当于 Dockerfile 里的
ENTRYPOINT指令。args:它是 command 运行时的参数,相当于 Dockerfile 里的
CMD指令,这两个命令和 Docker 的含义不同,要特别注意。
spec: | |
containers: | |
- image: busybox:latest | |
name: busy | |
imagePullPolicy: IfNotPresent | |
env: | |
- name: os | |
value: "ubuntu" | |
- name: debug | |
value: "on" | |
command: | |
- /bin/echo | |
args: | |
- "$(os), $(debug)" |
# 复制和执行命令
比如我有一个 “a.txt” 文件,那么就可以使用 kubectl cp 拷贝进 Pod 的 “/tmp” 目录里:
echo 'aaa' > a.txt | |
kubectl cp a.txt ngx-pod:/tmp |
不过 kubectl exec 的命令格式与 Docker 有一点小差异,需要在 Pod 后面加上 -- ,把 kubectl 的命令与 Shell 命令分隔开:
kubectl exec -it ngx-pod -- sh |
# Job-"临时任务"
apiVersion: batch/v1 | |
kind: Job | |
metadata: | |
name: echo-job | |
spec: | |
template: | |
spec: | |
restartPolicy: OnFailure | |
containers: | |
- image: busybox | |
name: echo-job | |
imagePullPolicy: IfNotPresent | |
command: ["/bin/echo"] | |
args: ["hello", "world"] |
spec字段里,多了一个template字段,然后又是一个spectemplate字段定义了一个 “应用模板” ,里面嵌入了一个 Pod,这样 Job 就可以从这个模板来创建出 Pod。

这里的 Pod 工作非常简单,在
containers里写好名字和镜像,command执行/bin/echo,输出 “hello world”。不过,因为 Job 业务的特殊性,所以我们还要在
spec里多加一个字段restartPolicy,确定 Pod 运行失败时的策略,OnFailure是失败原地重启容器,而Never则是不重启容器,让 Job 去重新调度生成一个新的 Pod。
再创建一个 Job 对象,名字叫 “sleep-job”,它随机睡眠一段时间再退出,模拟运行时间较长的作业(比如 MapReduce)。Job 的参数设置成 15 秒超时,最多重试 2 次,总共需要运行完 4 个 Pod,但同一时刻最多并发 2 个 Pod:
apiVersion: batch/v1 | |
kind: Job | |
metadata: | |
name: sleep-job | |
spec: | |
activeDeadlineSeconds: 15 # 设置 Pod 运行的超时时间 | |
backoffLimit: 2 # 设置 Pod 的失败重试次数 | |
completions: 4 # Job 完成需要运行多少个 Pod,默认是 1 个 | |
parallelism: 2 # 它与 completions 相关,表示允许并发运行的 Pod 数量,避免过多占用资源。 | |
# 这 4 个字段并不在 template 字段下,而是在 spec 字段下,所以它们是属于 Job 级别的,用来控制模板里的 Pod 对象。 | |
template: | |
spec: | |
restartPolicy: OnFailure # 失败原地重启容器 | |
containers: | |
- image: busybox | |
name: echo-job | |
imagePullPolicy: IfNotPresent | |
command: | |
- sh | |
- -c | |
- sleep $(($RANDOM % 10 + 1)) && echo done |
# CronJob-"定时任务"
- 简写
cj CronJob需要定时运行,所以我们在命令行里还需要指定参数--schedule
apiVersion: batch/v1 | |
kind: CronJob | |
metadata: | |
name: echo-cj | |
spec: | |
schedule: '*/1 * * * *' | |
jobTemplate: | |
spec: | |
template: | |
spec: | |
restartPolicy: OnFailure | |
containers: | |
- image: busybox | |
name: echo-cj | |
imagePullPolicy: IfNotPresent | |
command: ["/bin/echo"] | |
args: ["hello", "world"] |
连续三个 spec 嵌套:
- 第一个
spec是 CronJob 自己的对象规格声明 - 第二个
spec从属于 “jobTemplate”,它定义了一个 Job 对象。 - 第三个
spec从属于 “template”,它定义了 Job 里运行的 Pod。
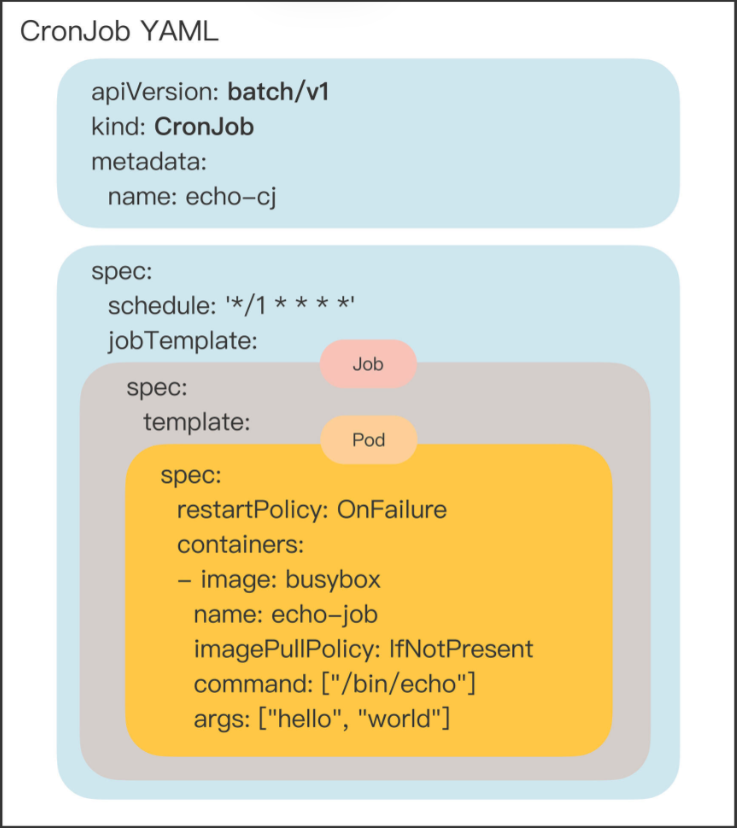
- 除了定义 Job 对象的 “jobTemplate” 字段之外,CronJob 还有一个新字段就是 “schedule”,用来定义任务周期运行的规则。
# ConfigMap/Secret
数据安全的角度来看可以分成两类:
一类是明文配置,也就是不保密,可以任意查询修改,比如服务端口、运行参数、文件路径等等。
另一类则是机密配置,由于涉及敏感信息需要保密,不能随便查看,比如密码、密钥、证书等等。
ConfigMap 用来保存明文配置,Secret 用来保存秘密配置 。
# ConfigMap
# 样板
apiVersion: v1 | |
kind: ConfigMap | |
metadata: | |
name: info |
没有
spec字段存储配置数据,不是容器,是静态的字符串
# data 字段
生成带有 “data” 字段的 YAML 样板:
kubectl create cm info --from-literal=k=v $out |
apiVersion: v1 | |
kind: ConfigMap | |
metadata: | |
name: info | |
data: | |
count: '10' | |
debug: 'on' | |
path: '/etc/systemd' | |
greeting: | | |
say hello to kubernetes. |
执行
kubectl apply -f cm.yml |
用 kubectl get 、 kubectl describe 来查看 ConfigMap 的状态:
kubectl get cm | |
kubectl describe cm info |
# Secret
它和 ConfigMap 的结构和用法很类似,不过在 Kubernetes 里 Secret 对象又细分出很多类,比如:
访问私有镜像仓库的认证信息
身份识别的凭证信息
HTTPS 通信的证书和私钥
一般的机密信息(格式由用户自行解释)
# 样板
创建 YAML 样板:
kubectl create secret generic user --from-literal=name=root $out |
apiVersion: v1 | |
kind: Secret | |
metadata: | |
name: user | |
data: | |
name: cm9vdA== |
- name 后面不是 root,而是乱码,实际上经过了 base64 加密。
也可以自己加密,写成 yaml 文件:
echo -n "123456" | base64 | |
MTIzNDU2 |
-n用于去掉隐藏的换行符
创建和查看:
kubectl apply -f secret.yml | |
kubectl get secret | |
kubectl describe secret user |
# 如何使用
因为 ConfigMap 和 Secret 只是一些存储在 etcd 里的字符串,所以如果想要在运行时产生效果,就必须要以某种方式 “注入” 到 Pod 里,让应用去读取。
# 环境变量
containers 里有一个 env , 除了可以使用简单的 value , 还可以使用 valueFrom
“valueFrom” 字段指定了环境变量值的来源,可以是 “configMapKeyRef” 或者 “secretKeyRef”,然后你要再进一步指定应用的 ConfigMap/Secret 的 “name” 和它里面的 “key”。
要当心的是这个 “name” 字段是 API 对象的名字,而不是 Key-Value 的名字。
apiVersion: v1 | |
kind: Pod | |
metadata: | |
name: env-pod | |
spec: | |
containers: | |
- env: | |
- name: COUNT | |
valueFrom: | |
configMapKeyRef: | |
name: info | |
key: count | |
- name: GREETING | |
valueFrom: | |
configMapKeyRef: | |
name: info | |
key: greeting | |
- name: USERNAME | |
valueFrom: | |
secretKeyRef: | |
name: user | |
key: name | |
- name: PASSWORD | |
valueFrom: | |
secretKeyRef: | |
name: user | |
key: pwd | |
image: busybox | |
name: busy | |
imagePullPolicy: IfNotPresent | |
command: ["/bin/sleep", "300"] |
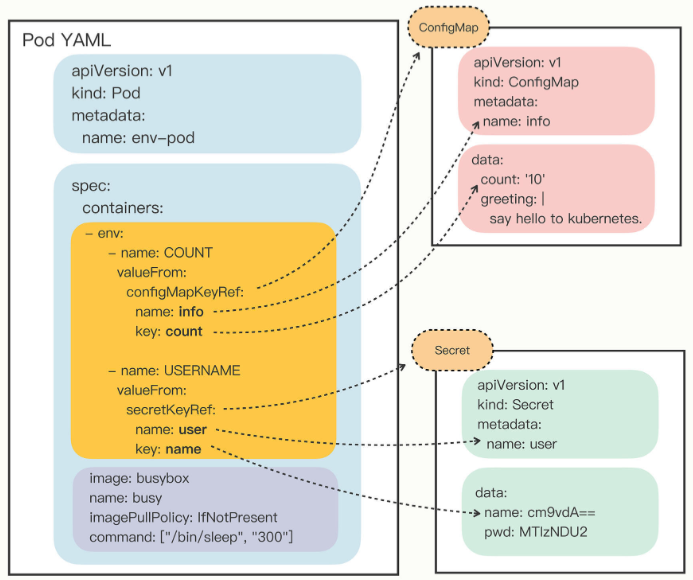
弄清楚了环境变量的注入方式之后,让我们用 kubectl apply 创建 Pod,再用 kubectl exec 进入 Pod,验证环境变量是否生效:
kubectl apply -f env-pod.yml | |
kubectl get pod | |
kubectl exec -it env-pod -- sh | |
echo $COUNT | |
10 | |
echo $GREETING | |
say hello to kubernetes | |
echo $USERNAME $PASSWORD | |
root 123456 |
# Volume - 存储卷
如果把 Pod 理解成是一个虚拟机,那么 Volume 就相当于是虚拟机里的磁盘。 我们可以为 Pod“挂载(mount)” 多个 Volume,里面存放供 Pod 访问的数据 。
- 只需要在
spec里增加一个volumes字段
apiVersion: v1 | |
kind: Pod | |
metadata: | |
name: vol-pod | |
spec: | |
volumes: | |
- name: cm-vol | |
configMap: | |
name: info | |
- name: sec-vol | |
secret: | |
secretName: user | |
containers: | |
- volumeMounts: | |
- mountPath: /tmp/cm-items # 指定挂载路径 | |
name: cm-vol # 指定 volume 名称 | |
- mountPath: /tmp/sec-items | |
name: sec-vol | |
image: busybox | |
name: busy | |
imagePullPolicy: IfNotPresent | |
command: ["/bin/sleep", "300"] |
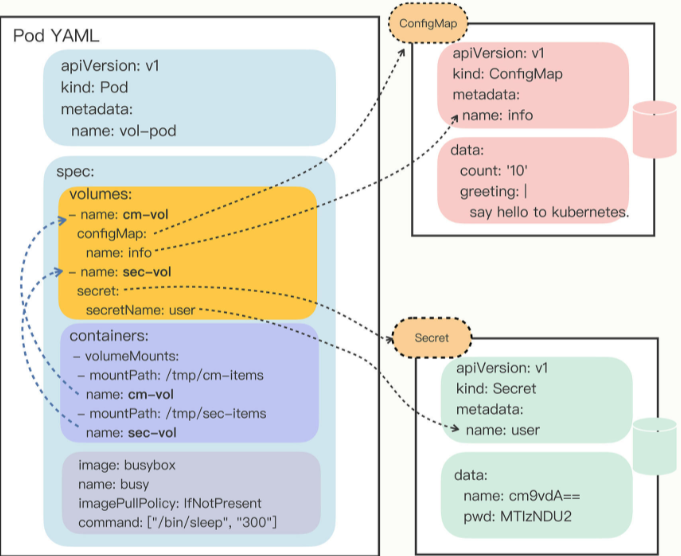
进去看看:
kubectl apply -f vol-pod.yml | |
kubectl get pod | |
kubectl exec -it vol-pod -- sh | |
/ # ls /tmp/cm-items/ | |
count debug greeting path | |
/ # cat /tmp/cm-items/greeting | |
say hello to kubernetes. |
# 总结
ConfigMap 和 Secret 对存储数据的大小没有限制,但小数据用环境变量比较适合,大数据应该用存储卷,可根据具体场景灵活应用。
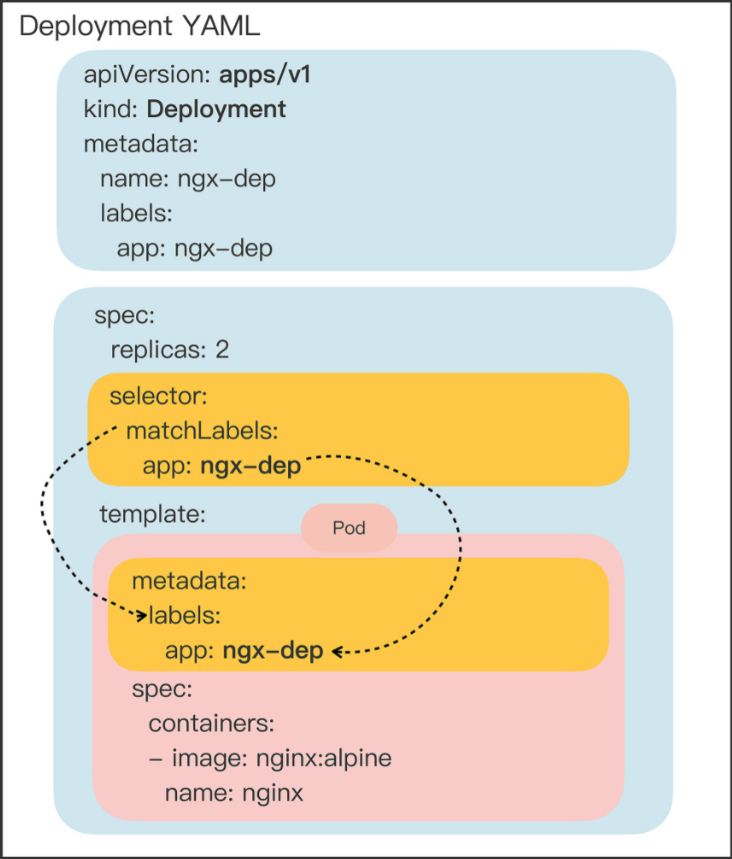
# Deployment
能够创建任意多个的 Pod 实例,并且维护这些 Pod 的正常运行,保证应用始终处于可用状态。
# 样板
apiVersion: apps/v1 | |
kind: Deployment | |
metadata: | |
labels: | |
app: ngx-dep | |
name: ngx-dep | |
spec: | |
replicas: 2 | |
selector: | |
matchLabels: | |
app: ngx-dep | |
template: | |
metadata: | |
labels: | |
app: ngx-dep | |
spec: | |
containers: | |
- image: nginx:alpine | |
name: nginx |
- 它的 “spec” 部分多了
replicas、selector这两个新字段
# 字段
# replicas
万一有 Pod 发生意外消失了,数量不满足 “期望状态”,它就会通过 apiserver、scheduler 等核心组件去选择新的节点,创建出新的 Pod,直至数量与 “期望状态” 一致。
# selector
通过标签这种设计,Kubernetes 就解除了 Deployment 和模板里 Pod 的强绑定,把组合关系变成了 “弱引用”。
# 应用伸缩
kubectl scale --replicas=5 deploy ngx-dep |
# DaemonSet
但是有一些业务比较特殊,它们不是完全独立于系统运行的,而是与主机存在 “绑定” 关系,必须要依附于节点才能产生价值,比如说:
网络应用(如 kube-proxy),必须每个节点都运行一个 Pod,否则节点就无法加入 Kubernetes 网络。
监控应用(如 Prometheus),必须每个节点都有一个 Pod 用来监控节点的状态,实时上报信息。
日志应用(如 Fluentd),必须在每个节点上运行一个 Pod,才能够搜集容器运行时产生的日志数据。
安全应用,同样的,每个节点都要有一个 Pod 来执行安全审计、入侵检查、漏洞扫描等工作。
# 样板
apiVersion: apps/v1 | |
kind: DaemonSet | |
metadata: | |
name: redis-ds | |
labels: | |
app: redis-ds | |
spec: | |
selector: | |
matchLabels: | |
name: redis-ds | |
template: | |
metadata: | |
labels: | |
name: redis-ds | |
spec: | |
containers: | |
- image: redis:5-alpine | |
name: redis | |
ports: | |
- containerPort: 6379 |
- 没有 replicas
# 污点和容忍度
# 查看 Master 和 Worker 的状态
kubectl describe node |
kubectl describe node master | |
Name: master | |
Roles: control-plane,master | |
... | |
Taints: node-role.kubernetes.io/master:NoSchedule | |
... | |
kubectl describe node worker | |
Name: worker | |
Roles: <none> | |
... | |
Taints: <none> | |
... |
Master 节点默认有一个 taint ,名字是 node-role.kubernetes.io/master ,它的效果是 NoSchedule ,也就是说这个污点会拒绝 Pod 调度到本节点上运行,而 Worker 节点的 taint 字段则是空的。
# 怎么让 DaemonSet 在 Master 节点(或者任意其他节点)上运行了?
# 去除污点
kubectl taint node master node-role.kubernetes.io/master:NoSchedule-node/master untainted |
# 添加 pod 字段 tolerations
如果我们想让 DaemonSet 里的 Pod 能够在 Master 节点上运行,就要写出这样的一个 tolerations ,容忍节点的 node-role.kubernetes.io/master:NoSchedule 这个污点:
tolerations: | |
- key: node-role.kubernetes.io/master | |
effect: NoSchedule | |
operator: Exists |
# (添加污点)
kubectl taint node master node-role.kubernetes.io/master:NoSchedule |
# Service
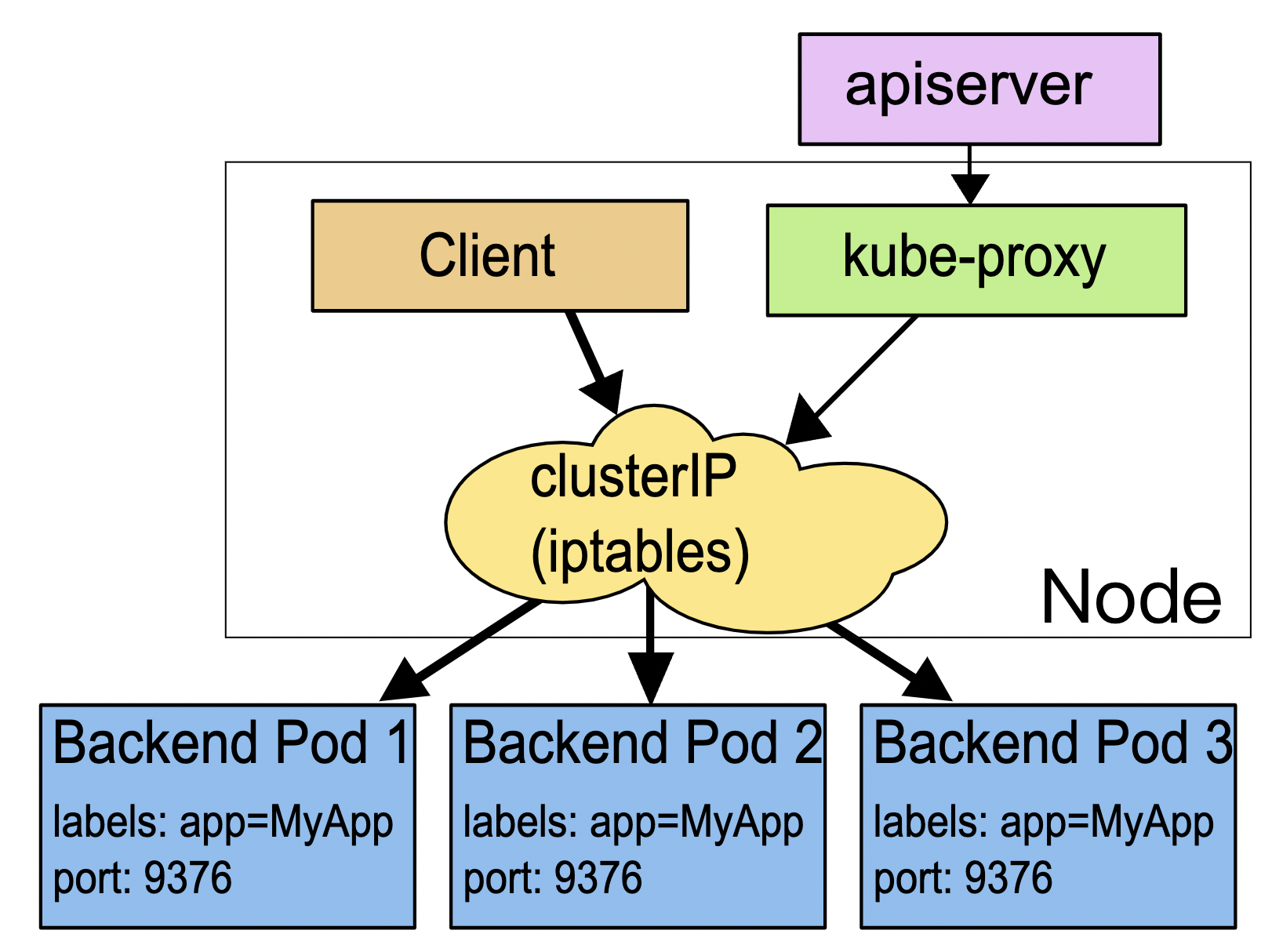
虽然它可以自动创建 YAML 样板,但不是用命令 kubectl create ,而是另外一个命令 kubectl expose ,也许 Kubernetes 认为 “expose” 能够更好地表达 Service “暴露” 服务地址的意思吧。
kubectl expose支持从多种对象创建服务,Pod、Deployment、DaemonSet 都可以。
使用 kubectl expose 指令时还需要用参数 --port 和 --target-port 分别指定映射端口和容器端口,而 Service 自己的 IP 地址和后端 Pod 的 IP 地址可以自动生成 。
# 样板
apiVersion: v1 | |
kind: Service | |
metadata: | |
name: ngx-svc | |
spec: | |
selector: | |
app: ngx-dep | |
ports: | |
- port: 80 # 外部端口 | |
targetPort: 80 # 内部端口 | |
protocol: TCP # 使用的协议 |

# 以域名的方式使用 service
查看命名空间
kubectl get ns |
Service 对象的域名完全形式是 “对象。名字空间.svc.cluster.local”,但很多时候也可以省略后面的部分,直接写 “对象。名字空间” 甚至 “对象名” 就足够了,默认会使用对象所在的名字空间 。
# 让 Service 对外暴露
Service 对象有一个关键字段 “type”,表示 Service 是哪种类型的负载均衡。前面我们看到的用法都是对集群内部 Pod 的负载均衡,所以这个字段的值就是默认的 “ClusterIP”,Service 的静态 IP 地址只能在集群内访问。
如果我们在使用命令 kubectl expose 的时候加上参数 --type=NodePort ,或者在 YAML 里添加字段 type:NodePort ,那么 Service 除了会对后端的 Pod 做负载均衡之外,还会在集群里的每个节点上创建一个独立的端口,用这个端口对外提供服务,这也正是 “NodePort” 这个名字的由来。
apiVersion: v1 | |
... | |
spec: | |
... | |
type: NodePort |

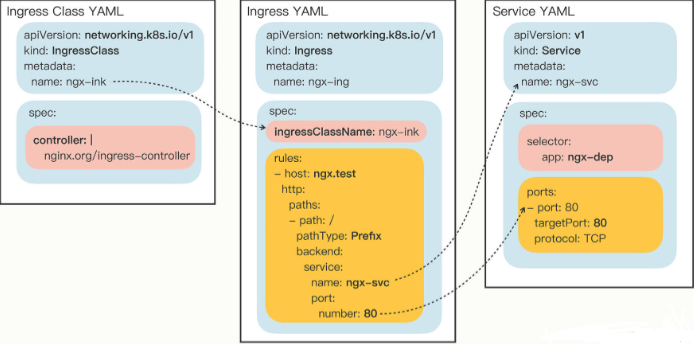
# Ingress/Ingress Class
# Ingress
# 样板
两个附加参数:
--class,指定 Ingress 从属的 Ingress Class 对象。--rule,指定路由规则,基本形式是 “URI=Service”,也就是说是访问 HTTP 路径就转发到对应的 Service 对象,再由 Service 对象转发给后端的 Pod。
export out="--dry-run=client -o yaml" | |
kubectl create ing ngx-ing --rule="ngx.test/=ngx-svc:80" --class=ngx-ink $out |
apiVersion: networking.k8s.io/v1 | |
kind: Ingress | |
metadata: | |
name: ngx-ing | |
spec: | |
ingressClassName: ngx-ink | |
rules: | |
- host: ngx.test | |
http: | |
paths: | |
- path: / | |
pathType: Exact # 路径的匹配方式 Exact 精确匹配 Prefix 前缀匹配 | |
backend: | |
service: | |
name: ngx-svc | |
port: | |
number: 80 |
# Ingress Class
# 样板
apiVersion: networking.k8s.io/v1 | |
kind: IngressClass | |
metadata: | |
name: ngx-ink | |
spec: | |
controller: nginx.org/ingress-controller |
spec 里只有一个必需的字段 controller ,表示要使用哪个 Ingress Controller,具体的名字就要看实现文档了。
比如,如果我要用 Nginx 开发的 Ingress Controller,那么就要用名字 nginx.org/ingress-controller
# 使用
# WordPress 部署
# 部署 MariaDB
apiVersion: v1 | |
kind: ConfigMap | |
metadata: | |
name: maria-cm | |
data: | |
DATABASE: 'db' | |
USER: 'wp' | |
PASSWORD: '123' | |
ROOT_PASSWORD: '123' | |
# 先要用 ConfigMap 定义数据库的环境变量,有 DATABASE、USER、PASSWORD、ROOT_PASSWORD | |
--- | |
apiVersion: apps/v1 | |
kind: Deployment | |
metadata: | |
labels: | |
app: maria-dep | |
name: maria-dep | |
spec: | |
replicas: 1 | |
selector: | |
matchLabels: | |
app: maria-dep | |
template: | |
metadata: | |
labels: | |
app: maria-dep | |
spec: | |
containers: | |
- image: mariadb:10 | |
name: mariadb | |
ports: | |
- containerPort: 3306 | |
envFrom: | |
- prefix: 'MARIADB_' | |
configMapRef: | |
name: maria-cm | |
--- | |
# 为 MariaDB 定义一个 Service 对象,映射端口 3306 | |
# 让其他应用不再关心 IP 地址,直接用 Service 对象的名字来访问数据库服务 | |
apiVersion: v1 | |
kind: Service | |
metadata: | |
labels: | |
app: maria-dep | |
name: maria-svc | |
spec: | |
ports: | |
- port: 3306 | |
protocol: TCP | |
targetPort: 3306 | |
selector: | |
app: maria-dep |
# 部署 WordPress
# 因为刚才创建了 MariaDB 的 Service,所以在写 ConfigMap 配置的时候 “HOST” 就不应该是 IP 地址了,而应该是 DNS 域名,也就是 Service 的名字 maria-svc,这点需要特别注意 | |
apiVersion: v1 | |
kind: ConfigMap | |
metadata: | |
name: wp-cm | |
data: | |
HOST: 'maria-svc' | |
USER: 'wp' | |
PASSWORD: '123' | |
NAME: 'db' | |
--- | |
# WordPress 的 Deployment 写法和 MariaDB 也是一样的,给 Pod 套一个 Deployment 的 “外壳”,replicas 设置成 2 个,用字段 “envFrom” 配置环境变量。 | |
apiVersion: apps/v1 | |
kind: Deployment | |
metadata: | |
labels: | |
app: wp-dep | |
name: wp-dep | |
spec: | |
replicas: 2 | |
selector: | |
matchLabels: | |
app: wp-dep | |
template: | |
metadata: | |
labels: | |
app: wp-dep | |
spec: | |
containers: | |
- image: wordpress:5 | |
name: wordpress | |
ports: | |
- containerPort: 80 | |
envFrom: | |
- prefix: 'WORDPRESS_DB_' | |
configMapRef: | |
name: wp-cm | |
--- | |
# 然后我们仍然要为 WordPress 创建 Service 对象,这里我使用了 “NodePort” 类型,并且手工指定了端口号 “30088”(必须在 30000~32767 之间) | |
apiVersion: v1 | |
kind: Service | |
metadata: | |
labels: | |
app: wp-dep | |
name: wp-svc | |
spec: | |
ports: | |
- name: http80 | |
port: 80 | |
protocol: TCP | |
targetPort: 80 | |
nodePort: 30088 | |
selector: | |
app: wp-dep | |
type: NodePort |
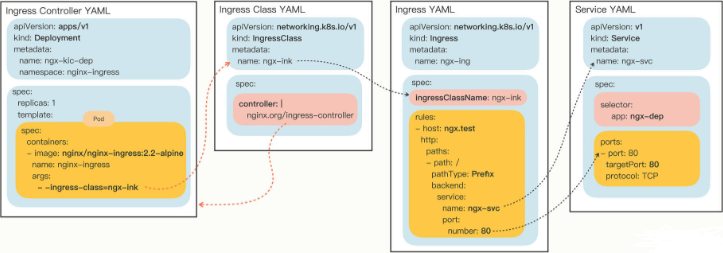
# 部署 Nginx Ingress Controller
# 首先我们需要定义 Ingress Class,名字就叫 “wp-ink” | |
apiVersion: networking.k8s.io/v1 | |
kind: IngressClass | |
metadata: | |
name: wp-ink | |
spec: | |
controller: nginx.org/ingress-controller | |
--- | |
# kubectl create ing wp-ing --rule="wp.test/=wp-svc:80" --class=wp-ink $out | |
apiVersion: networking.k8s.io/v1 | |
kind: Ingress | |
metadata: | |
name: wp-ing | |
spec: | |
ingressClassName: wp-ink | |
rules: | |
- host: wp.test | |
http: | |
paths: | |
- path: / | |
pathType: Prefix | |
backend: | |
service: | |
name: wp-svc | |
port: | |
number: 80 | |
--- | |
# 接下来就是最关键的 Ingress Controller 对象了,它仍然需要从 Nginx 项目的示例 YAML 修改而来,要改动名字、标签,还有参数里的 Ingress Class。 | |
# 在之前讲基本架构的时候我说过了,这个 Ingress Controller 不使用 Service,而是给它的 Pod 加上一个特殊字段 hostNetwork,让 Pod 能够使用宿主机的网络,相当于另一种形式的 NodePort。 | |
apiVersion: apps/v1 | |
kind: Deployment | |
metadata: | |
name: wp-kic-dep | |
namespace: nginx-ingress | |
spec: | |
replicas: 1 | |
selector: | |
matchLabels: | |
app: wp-kic-dep | |
template: | |
metadata: | |
labels: | |
app: wp-kic-dep | |
spec: | |
serviceAccountName: nginx-ingress | |
hostNetwork: true | |
containers: | |
- image: nginx/nginx-ingress:2.2-alpine | |
name: nginx-ingress | |
args: | |
- -ingress-class=wp-ink |
# 数据持久化
# PersistentVolume
- 由于临时存储,pod 销毁后数据会丢失
PersistentVolume对象,它专门用来表示持久存储设备,但隐藏了存储的底层实现- PV 属于集群的系统资源,是和 Node 平级的一种对象,Pod 对它没有管理权,只有使用权
# PersistentVolumeClaim
PersistentVolumeClaim ,简称 PVC,从名字上看比较好理解,就是用来向 Kubernetes 申请存储资源的。PVC 是给 Pod 使用的对象,它相当于是 Pod 的代理,代表 Pod 向系统申请 PV。一旦资源申请成功,Kubernetes 就会把 PV 和 PVC 关联在一起,这个动作叫做 “绑定”(bind)。
# StorageClass
它抽象了特定类型的存储系统(比如 Ceph、NFS),在 PVC 和 PV 之间充当 “协调人” 的角色,帮助 PVC 找到合适的 PV。也就是说它可以简化 Pod 挂载 “虚拟盘” 的过程,让 Pod 看不到 PV 的实现细节。
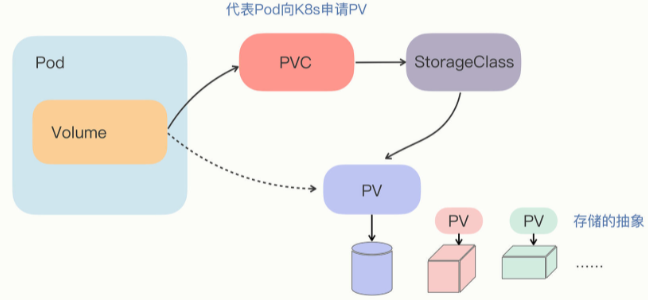
# 描述 PV
# 样板
apiVersion: v1 | |
kind: PersistentVolume | |
metadata: | |
name: host-10m-pv | |
spec: | |
storageClassName: host-test | |
accessModes: | |
- ReadWriteOnce | |
capacity: | |
storage: 10Mi | |
hostPath: | |
path: /tmp/host-10m-pv/ |
因为 Pod 会在集群的任意节点上运行,所以首先,我们要作为系统管理员在每个节点上创建一个目录,它将会作为本地存储卷挂载到 Pod 里。
# 字段解释
storageClassName 对存储类型的抽象
StorageClassaccessModes 定义了存储设备的访问模式,简单来说就是虚拟盘的读写权限,和 Linux 的文件访问模式差不多,目前 Kubernetes 里有 3 种:
- ReadWriteOnce:存储卷可读可写,但只能被一个节点上的 Pod 挂载。
- ReadOnlyMany:存储卷只读不可写,可以被任意节点上的 Pod 多次挂载。
- ReadWriteMany:存储卷可读可写,也可以被任意节点上的 Pod 多次挂载。
这 3 种访问模式限制的对象是节点而不是 Pod
显然,本地目录只能是在本机使用,所以这个 PV 使用了
ReadWriteOncecapacity 表示存储设备的容量(Kubernetes 里定义存储容量使用的是国际标准,我们日常习惯使用的 KB/MB/GB 的基数是 1024,要写成 Ki/Mi/Gi,一定要小心不要写错了,否则单位不一致实际容量就会对不上。)
hostPath 指定了存储卷的本地路径,也就是我们在节点上创建的目录。
# 描述 PVC
# 样板
apiVersion: v1 | |
kind: PersistentVolumeClaim | |
metadata: | |
name: host-5m-pvc | |
spec: | |
storageClassName: host-test | |
accessModes: | |
- ReadWriteOnce | |
resources: | |
requests: | |
storage: 5Mi |
# 字段解释
PVC 的内容与 PV 很像,但它不表示实际的存储,而是一个 “申请” 或者 “声明”,spec 里的字段描述的是对存储的 “期望状态”
storageClassNameaccessModescapacity和 PV 一样没有capacityresources.request 表示希望要有多大的容量
这样,Kubernetes 就会根据 PVC 里的描述,去找能够匹配 StorageClass 和容量的 PV,然后把 PV 和 PVC “绑定” 在一起,实现存储的分配 。
# 使用
# 创建 PV 对象 | |
kubectl apply -f host-path-pv.yml | |
# 查看状态 | |
kubectl get pv | |
# 创建 PVC 对象,申请储存资源 | |
kubectl apply -f host-path-pvc.yml | |
kubectl get pvc |
一旦 PVC 对象创建成功,Kubernetes 就会立即通过 StorageClass、resources 等条件在集群里查找符合要求的 PV,如果找到合适的存储对象就会把它俩 “绑定” 在一起。
# 为 Pod 挂载 PV
先要在
spec.volumes定义存储卷,然后在containers.volumeMounts挂载进容器要在 volumes 里用字段 persistentVolumeClaim 指定 PVC 的名字
apiVersion: v1 | |
kind: Pod | |
metadata: | |
name: host-pvc-pod | |
spec: | |
volumes: | |
- name: host-pvc-vol | |
persistentVolumeClaim: | |
claimName: host-5m-pvc # 指定 PVC 名字 | |
containers: | |
- name: ngx-pvc-pod | |
image: nginx:alpine | |
ports: | |
- containerPort: 80 | |
volumeMounts: | |
- name: host-pvc-vol | |
mountPath: /tmp # 挂载路径 |
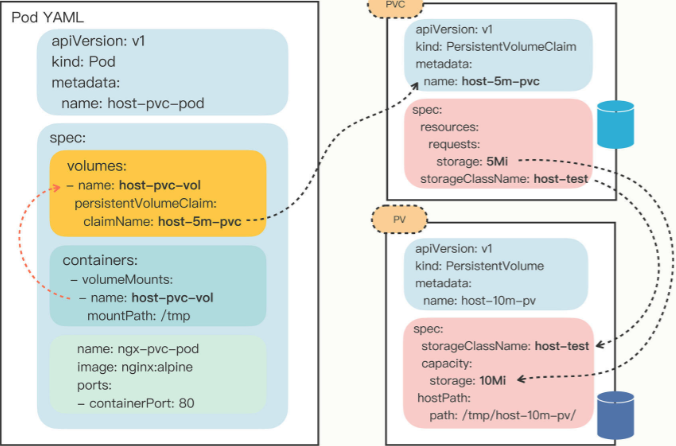
因为 Pod 产生的数据已经通过 PV 存在了磁盘上,所以如果 Pod 删除后再重新创建,挂载存储卷时会依然使用这个目录,数据保持不变,也就实现了持久化存储。
# 缺点
- 因为这个 PV 是 HostPath 类型,只在本节点存储,如果 Pod 重建时被调度到了其他节点上,那么即使加载了本地目录,也不会是之前的存储位置,持久化功能也就失效了
- 所以,HostPath 类型的 PV 一般用来做测试,或者是用于 DaemonSet 这样与节点关系比较密切的应用
# 总结
PersistentVolume 简称为 PV,是 Kubernetes 对存储设备的抽象,由系统管理员维护,需要描述清楚存储设备的类型、访问模式、容量等信息。
PersistentVolumeClaim 简称为 PVC,代表 Pod 向系统申请存储资源,它声明对存储的要求,Kubernetes 会查找最合适的 PV 然后绑定。
StorageClass 抽象特定类型的存储系统,归类分组 PV 对象,用来简化 PV/PVC 的绑定过程。
HostPath 是最简单的一种 PV,数据存储在节点本地,速度快但不能跟随 Pod 迁移。
# PV+NFS - 网络共享存储
# 安装 NFS 服务器和客户端
详见同一类别下另一篇
# 使用 NFS 存储卷
# nfs-static-pv.yml | |
apiVersion: v1 | |
kind: PersistentVolume | |
metadata: | |
name: nfs-1g-pv | |
spec: | |
storageClassName: nfs | |
accessModes: | |
- ReadWriteMany | |
capacity: | |
storage: 1Gi | |
nfs: | |
path: /tmp/nfs/1g-pv # 共享目录名,路径须提前在服务端创建好 | |
server: 192.168.10.104 # 服务端主机 | |
# 注意:不需要挂载本机目录 |
需要指定
storageClassName是nfs,而accessModes可以设置成ReadWriteMany,这是由NFS的特性决定的,它支持多个节点同时访问一个共享目录因为这个存储卷是
NFS系统,所以我们还需要在YAML里添加nfs字段,指定NFS服务器的IP地址和共享目录名这里在
NFS服务器的/tmp/nfs目录里又创建了一个新的目录1g-pv,表示分配了 1GB 的可用存储空间,相应的,PV里的capacity也要设置成同样的数值,也就是 1Gi
用 pvc 申请储存
# nfs-static-pvc.yml | |
apiVersion: v1 | |
kind: PersistentVolumeClaim | |
metadata: | |
name: nfs-static-pvc | |
spec: | |
storageClassName: nfs | |
accessModes: | |
- ReadWriteMany | |
resources: | |
requests: | |
storage: 1Gi |
# nfs-static-pod.yml | |
apiVersion: v1 | |
kind: Pod | |
metadata: | |
name: nfs-static-pod | |
spec: | |
volumes: | |
- name: nfs-pvc-vol | |
persistentVolumeClaim: | |
claimName: nfs-static-pvc | |
containers: | |
- name: nfs-pvc-test | |
image: nginx:alpine | |
ports: | |
- containerPort: 80 | |
volumeMounts: | |
- name: nfs-pvc-vol | |
mountPath: /tmp # 把 pod 的 /tmp 目录挂载到 nfs 服务端 即 /tmp/ 数据会写入共享目录 |
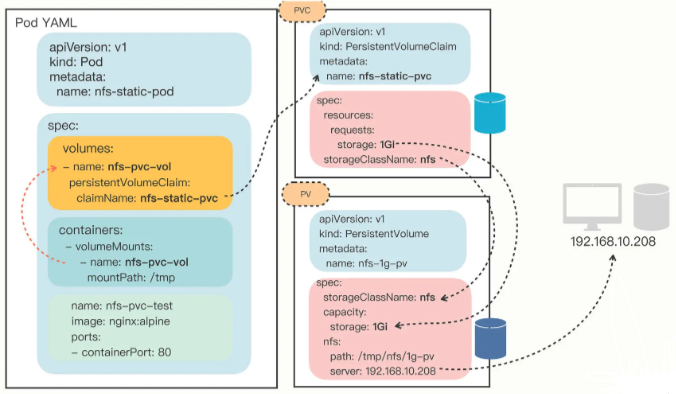
# 部署 NFS 动态存储卷
# 使用 NFS 动态存储卷
因为有了 Provisioner ,我们就不再需要手工定义 PV 对象了,只需要在 PVC 里指定 StorageClass 对象,它再关联到 Provisioner
我们来看一下 NFS 默认的 StorageClass 定义:
apiVersion: storage.k8s.io/v1 | |
kind: StorageClass | |
metadata: | |
name: nfs-client | |
provisioner: k8s-sigs.io/nfs-subdir-external-provisioner | |
parameters: | |
archiveOnDelete: "false" |
YAML 里的关键字段是 provisioner,它指定了应该使用哪个 Provisioner。另一个字段 parameters 是调节 Provisioner 运行的参数,需要参考文档来确定具体值,在这里的 archiveOnDelete: "false" 就是自动回收存储空间。
你也可以不使用默认的 StorageClass,而是根据自己的需求,任意定制具有不同存储特性的 StorageClass,比如添加字段 onDelete: "retain" 暂时保留分配的存储,之后再手动删除:
apiVersion: storage.k8s.io/v1 | |
kind: StorageClass | |
metadata: | |
name: nfs-client-retained | |
provisioner: k8s-sigs.io/nfs-subdir-external-provisioner | |
parameters: | |
onDelete: "retain" |
接下来我们定义一个 PVC ,向系统申请 10MB 的存储空间,使用的 StorageClass 是默认的 nfs-client
apiVersion: v1 | |
kind: PersistentVolumeClaim | |
metadata: | |
name: nfs-dyn-10m-pvc | |
spec: | |
storageClassName: nfs-client | |
accessModes: | |
- ReadWriteMany | |
resources: | |
requests: | |
storage: 10Mi |
写好了 PVC ,我们还是在 Pod 里用 volumes 和 volumeMounts 挂载,然后 Kubernetes 就会自动找到 NFS Provisioner ,在 NFS 的共享目录上创建出合适的 PV 对象
apiVersion: v1 | |
kind: Pod | |
metadata: | |
name: nfs-dyn-pod | |
spec: | |
volumes: | |
- name: nfs-dyn-10m-vol | |
persistentVolumeClaim: | |
claimName: nfs-dyn-10m-pvcSnipaste_2024-02-13_18-04-00 | |
containers: | |
- name: nfs-dyn-test | |
image: nginx:alpine | |
ports: | |
- containerPort: 80 | |
volumeMounts: | |
- name: nfs-dyn-10m-vol | |
mountPath: /tmp |
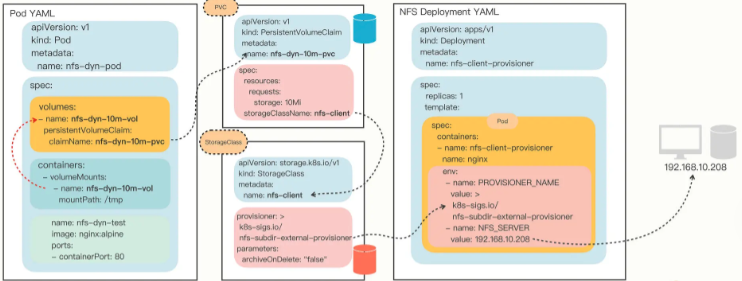
# 总结
本节我们引入了网络存储系统,以 NFS 为例研究了静态存储卷和动态存储卷的用法,其中的核心对象是 StorageClass 和 Provisioner。
在 Kubernetes 集群里,网络存储系统更适合数据持久化,NFS 是最容易使用的一种网络存储系统,要事先安装好服务端和客户端。
可以编写 PV 手工定义 NFS 静态存储卷,要指定 NFS 服务器的 IP 地址和共享目录名。
使用 NFS 动态存储卷必须要部署相应的 Provisioner,在 YAML 里正确配置 NFS 服务器。
动态存储卷不需要手工定义 PV,而是要定义 StorageClass,由关联的 Provisioner 自动创建 PV 完成绑定。
StorageClass 里面的 OnDelete 、 archiveOnDelete 源自 PV 的存储回收策略,指定 PV 被销毁时数据是保留 Retain 还是 删除 Delete。
# StorageClass 的作用
StorageClass 作用是帮助指定特定类型的 provisioner,这决定了你要使用的具体某种类型的存储插件;另外它还限定了 PV 和 PVC 的绑定关系,只有从属于同一 StorageClass 的 PV 和 PVC 才能做绑定动作,比如指定 GlusterFS 类型的 PVC 对象不能绑定到另外一个 PVC 定义的 NFS 类型的 StorageClass 模版创建出的 Volume 的 PV 对象上面去。
StorageClass 应证了 “所有问题都可以通过增加一层来解决”。作用是解决了特定底层存储与 K8S 上资源的解耦问题,通过 SC 统一接口,具体厂商负责具体的存储实现。
因为存储它涉及到了对物理机文件系统绑定的操作,因此 K8S 做了一系列抽象。PV 在这个抽象里,其实就指代了主机文件系统的路径,当然至于再往实现层面走,是网络文件系统还是主机文件系统,这就全由 PV 的绑定类型决定。而往抽象层走,作为 K8S 的核心系统,K8S 想尽可能屏蔽掉底层,也就是主机文件系统的概念,所以它抽象了 StorageClass ,用来统一指代 / 管理 PV 。至此,K8S 持久化存储就可以分两个部分:
第一部分是由 主机文件系统 + PV+StorageClass 组成的,用来将抽象对象绑定到真实文件系统的生产者部分;
第二部分就是 Volume+PVC+StorageClass,完全被抽象为 K8S 核心业务的消费者部分,而 StorageClass,可以看作是两部分连接的桥梁。
# StatefulSet - 管理有状态的应用
对于 “有状态应用”(如 mysql,redis),多个实例之间可能存在依赖关系,比如 master/slave、active/passive,需要依次启动才能保证应用正常运行,外界的客户端也可能要使用固定的网络标识来访问实例,而且这些信息还必须要保证在 Pod 重启后不变 。
- StatefulSet 也可以看做是 Deployment 的一个特例
# 样板
apiVersion: apps/v1 | |
kind: StatefulSet | |
metadata: | |
name: redis-sts | |
spec: | |
serviceName: redis-svc | |
replicas: 2 | |
selector: | |
matchLabels: | |
app: redis-sts | |
template: | |
metadata: | |
labels: | |
app: redis-sts | |
spec: | |
containers: | |
- image: redis:5-alpine | |
name: redis | |
ports: | |
- containerPort: 6379 |
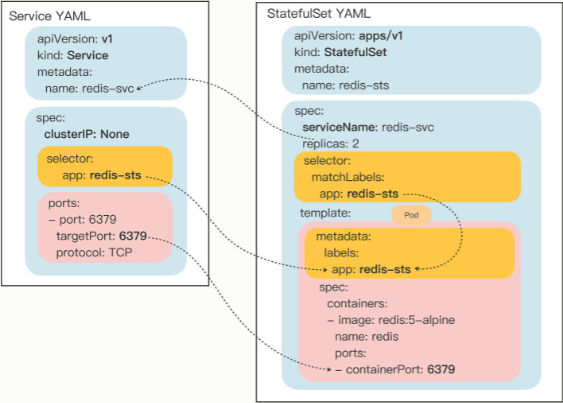
spec里多出serviceName其余和
deployment相同
# 使用 StatefulSet
写 service,metadata.name 必须和 StatefulSet 里的 serviceName 相同,selector 里的标签也必须和 StatefulSet 里的一致 。
apiVersion: v1 | |
kind: Service | |
metadata: | |
name: redis-svc | |
spec: | |
selector: | |
app: redis-sts | |
ports: | |
- port: 6379 | |
protocol: TCP | |
targetPort: 6379 |
- Service 自己会有一个域名,格式是 “对象名。名字空间”
- Service 发现这些 Pod 不是一般的应用,而是有状态应用,需要有稳定的网络标识,所以就会为 Pod 再多创建出一个新的域名,格式是 “Pod 名。服务名。名字空间.svc.cluster.local”。当然,这个域名也可以简写成 “Pod 名。服务名”。
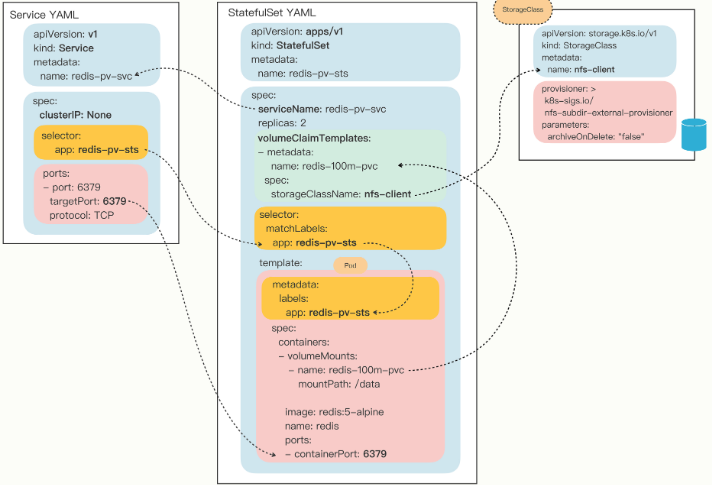
# StatefulSet 的数据持久化
为了强调持久化存储与 StatefulSet 的一对一绑定关系,Kubernetes 为 StatefulSet 专门定义了一个字段 “volumeClaimTemplates”,直接把 PVC 定义嵌入 StatefulSet 的 YAML 文件里。这样能保证创建 StatefulSet 的同时,就会为每个 Pod 自动创建 PVC,让 StatefulSet 的可用性更高。
apiVersion: apps/v1 | |
kind: StatefulSet | |
metadata: | |
name: redis-pv-sts | |
spec: | |
serviceName: redis-pv-svc | |
volumeClaimTemplates: # pvc | |
- metadata: | |
name: redis-100m-pvc | |
spec: | |
storageClassName: nfs-client | |
accessModes: | |
- ReadWriteMany | |
resources: | |
requests: | |
storage: 100Mi | |
replicas: 2 | |
selector: | |
matchLabels: | |
app: redis-pv-sts # 对应 svc 的名字 | |
template: | |
metadata: | |
labels: | |
app: redis-pv-sts | |
spec: | |
containers: | |
- image: redis:5-alpine | |
name: redis | |
ports: | |
- containerPort: 6379 | |
volumeMounts: | |
- name: redis-100m-pvc | |
mountPath: /data |
# 总结
我们学习了专门部署 “有状态应用” 的 API 对象 StatefulSet,它与 Deployment 非常相似,区别是由它管理的 Pod 会有固定的名字、启动顺序和网络标识,这些特性对于在集群里实施有主从、主备等关系的应用非常重要。
StatefulSet 的 YAML 描述和 Deployment 几乎完全相同,只是多了一个关键字段
serviceName。要为 StatefulSet 里的 Pod 生成稳定的域名,需要定义 Service 对象,它的名字必须和 StatefulSet 里的
serviceName一致。访问 StatefulSet 应该使用每个 Pod 的单独域名,形式是 “Pod 名。服务名”,不应该使用 Service 的负载均衡功能。
在 StatefulSet 里可以用字段 “volumeClaimTemplates” 直接定义 PVC,让 Pod 实现数据持久化存储。
# 滚动更新 - 平滑的应用升级
在 Kubernetes 里应用都是以 Pod 的形式运行的,而 Pod 通常又会被 Deployment 等对象来管理,所以应用的 “版本更新” 实际上更新的是整个 Pod。
# 滚动更新条件
- 镜像版本更新
- 镜像名称不变(可以再创建一个 yaml 文件)
# 常用命令
# 查看应用更新的状态 | |
kubectl rollout status deploy mysql-dep-test | |
# 查看 pod 变化情况 | |
kubectl describe deploy mysql-dep-test | |
# 暂停更新 | |
kubectl rollout pause deploy mysql-dep-test | |
# 继续更新 | |
kubectl rollout resume deploy mysql-dep-test | |
# 查看更新历史 | |
kubectl rollout history deploy mysql-dep-test | |
# 查看每个版本详细信息 | |
kubectl rollout history deploy mysql-dep-test --revision=4 | |
# 回退版本 | |
kubectl rollout undo deploy mysql-dep-test | |
# 回退版本 - 指定版本 | |
kubectl rollout undo deploy mysql-dep-test --to-revision=2 |
# 添加更新描述
apiVersion: apps/v1 | |
kind: Deployment | |
metadata: | |
name: ngx-dep | |
annotations: | |
kubernetes.io/change-cause: v1, ngx=1.21 | |
... ... | |
apiVersion: apps/v1 | |
kind: Deployment | |
metadata: | |
name: ngx-dep | |
annotations: | |
kubernetes.io/change-cause: update to v2, ngx=1.22 | |
... ... | |
apiVersion: apps/v1 | |
kind: Deployment | |
metadata: | |
name: ngx-dep | |
annotations: | |
kubernetes.io/change-cause: update to v3, change name | |
... ... |
annotations里的值可以任意写,Kubernetes 会自动忽略不理解的 Key-Value,但要编写更新说明就需要使用特定的字段kubernetes.io/change-cause
# 健康运行
# 容器资源配额
只要在 Pod 容器的描述部分添加一个新字段 resources 即可
apiVersion: v1 | |
kind: Pod | |
metadata: | |
name: ngx-pod-resources | |
spec: | |
containers: | |
- image: nginx:alpine | |
name: ngx | |
resources: | |
requests: | |
cpu: 10m | |
memory: 100Mi | |
limits: | |
cpu: 20m | |
memory: 200Mi |
“requests”,意思是容器要申请的资源,也就是说要求 Kubernetes 在创建 Pod 的时候必须分配这里列出的资源,否则容器就无法运行。
“limits”,意思是容器使用资源的上限,不能超过设定值,否则就有可能被强制停止运行。
而 CPU 因为在计算机中数量有限,非常宝贵,所以 Kubernetes 允许容器精细分割 CPU,即可以 1 个、2 个地完整使用 CPU,也可以用小数 0.1、0.2 的方式来部分使用 CPU。这其实是效仿了 UNIX “时间片” 的用法,意思是进程最多可以占用多少 CPU 时间。
不过 CPU 时间也不能无限分割,Kubernetes 里 CPU 的最小使用单位是 0.001,为了方便表示用了一个特别的单位 m,也就是 “milli”“毫” 的意思,比如说 500m 就相当于 0.5。
现在我们再来看这个 YAML,你就应该明白了,它向系统申请的是 1% 的 CPU 时间和 100MB 的内存,运行时的资源上限是 2% CPU 时间和 200MB 内存。
如果 Pod 不写 resources 字段,Kubernetes 会如何处理呢?
这就意味着 Pod 对运行的资源要求 “既没有下限,也没有上限”,Kubernetes 不用管 CPU 和内存是否足够,可以把 Pod 调度到任意的节点上,而且后续 Pod 运行时也可以无限制地使用 CPU 和内存。
# 容器状态探针
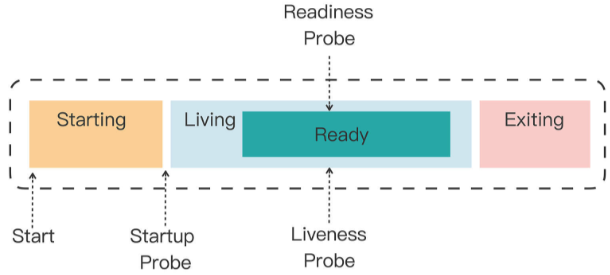
Kubernetes 为检查应用状态定义了三种探针,它们分别对应容器不同的状态:
Startup,启动探针,用来检查应用是否已经启动成功,适合那些有大量初始化工作要做,启动很慢的应用。
Liveness,存活探针,用来检查应用是否正常运行,是否存在死锁、死循环。
Readiness,就绪探针,用来检查应用是否可以接收流量,是否能够对外提供服务。
这三种探针是递进的关系:应用程序先启动,加载完配置文件等基本的初始化数据就进入了 Startup 状态,之后如果没有什么异常就是 Liveness 存活状态,但可能有一些准备工作没有完成,还不一定能对外提供服务,只有到最后的 Readiness 状态才是一个容器最健康可用的状态。
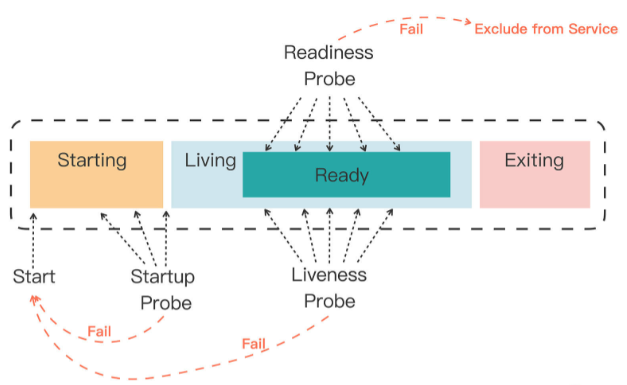
如果一个 Pod 里的容器配置了探针,Kubernetes 在启动容器后就会不断地调用探针来检查容器的状态:
如果 Startup 探针失败,Kubernetes 会认为容器没有正常启动,就会尝试反复重启,当然其后面的 Liveness 探针和 Readiness 探针也不会启动。
如果 Liveness 探针失败,Kubernetes 就会认为容器发生了异常,也会重启容器。
如果 Readiness 探针失败,Kubernetes 会认为容器虽然在运行,但内部有错误,不能正常提供服务,就会把容器从 Service 对象的负载均衡集合中排除,不会给它分配流量。
# 如何使用容器状态探针
startupProbe、livenessProbe、readinessProbe 这三种探针的配置方式都是一样的,关键字段有这么几个:
- periodSeconds,执行探测动作的时间间隔,默认是 10 秒探测一次。
- timeoutSeconds,探测动作的超时时间,如果超时就认为探测失败,默认是 1 秒。
- successThreshold,连续几次探测成功才认为是正常,对于 startupProbe 和 livenessProbe 来说它只能是 1。
- failureThreshold,连续探测失败几次才认为是真正发生了异常,默认是 3 次。
至于探测方式,Kubernetes 支持 3 种:Shell、TCP Socket、HTTP GET,它们也需要在探针里配置:
- exec,执行一个 Linux 命令,比如 ps、cat 等等,和 container 的 command 字段很类似。
- tcpSocket,使用 TCP 协议尝试连接容器的指定端口。
- httpGet,连接端口并发送 HTTP GET 请求。
# 示例
ConfigMap
apiVersion: v1 | |
kind: ConfigMap | |
metadata: | |
name: ngx-conf | |
data: | |
default.conf: | | |
server { | |
listen 80; | |
location = /ready { | |
return 200 'I am ready'; | |
} | |
} | |
# 启用了 80 端口,然后用 location 指令定义了 HTTP 路径 /ready,它作为对外暴露的 “检查口”,用来检测就绪状态,返回简单的 200 状态码和一个字符串表示工作正常。 |
Pod
apiVersion: v1 | |
kind: Pod | |
metadata: | |
name: ngx-pod-probe | |
spec: | |
volumes: | |
- name: ngx-conf-vol | |
configMap: | |
name: ngx-conf | |
containers: | |
- image: nginx:alpine | |
name: ngx | |
ports: | |
- containerPort: 80 | |
volumeMounts: | |
- mountPath: /etc/nginx/conf.d | |
name: ngx-conf-vol | |
startupProbe: | |
periodSeconds: 1 | |
exec: | |
command: ["cat", "/var/run/nginx.pid"] | |
# StartupProbe 使用了 Shell 方式,使用 cat 命令检查 Nginx 存在磁盘上的进程号文件(/var/run/nginx.pid),如果存在就认为是启动成功,它的执行频率是每秒探测一次。 | |
livenessProbe: | |
periodSeconds: 10 | |
tcpSocket: | |
port: 80 | |
# LivenessProbe 使用了 TCP Socket 方式,尝试连接 Nginx 的 80 端口,每 10 秒探测一次。 | |
readinessProbe: | |
periodSeconds: 5 | |
httpGet: | |
path: /ready | |
port: 80 | |
# ReadinessProbe 使用的是 HTTP GET 方式,访问容器的 /ready 路径,每 5 秒发一次请求。 |
# 名字空间
**Kubernetes 的名字空间并不是一个实体对象,只是一个逻辑上的概念。** 它可以把集群切分成一个个彼此独立的区域,然后我们把对象放到这些区域里,就实现了类似容器技术里 namespace 的隔离效果,应用只能在自己的名字空间里分配资源和运行,不会干扰到其他名字空间里的应用。
# 创建名字空间 | |
kubectl create ns test-ns | |
# 获取名字空间 | |
kubectl get ns |
也可以这样创建名字空间
apiVersion: v1 | |
kind: Namespace | |
metadata: | |
name: dev-ns |
想要把一个对象放入特定的名字空间,需要在它的 metadata 里添加一个 namespace 字段
apiVersion: v1 | |
kind: Pod | |
metadata: | |
name: ngx | |
namespace: test-ns | |
spec: | |
containers: | |
- image: nginx:alpine | |
name: ngx |
想要操作其他名字空间的对象必须要用 -n 参数明确指定
kubectl get pod -n test-ns |
一旦名字空间被删除,它里面的所有对象也都会消失
kubectl delete ns test-ns |
# 资源配额 - ResourceQuota
有了名字空间,我们就可以像管理容器一样,给名字空间设定配额,把整个集群的计算资源分割成不同的大小,按需分配给团队或项目使用
名字空间的资源配额需要使用一个专门的 API 对象,叫做 ResourceQuota,简称是 quota
ResourceQuota 对象的使用方式比较灵活,既可以限制整个名字空间的配额,也可以只限制某些类型的对象(使用 scopeSelector),今天我们看第一种,它需要在 spec 里使用 hard 字段,意思就是 “硬性全局限制”。
# 样板
apiVersion: v1 | |
kind: ResourceQuota | |
metadata: | |
name: dev-qt | |
namespace: dev-ns | |
spec: | |
hard: | |
# 所有 Pod 的需求总量最多是 10 个 CPU 和 10GB 的内存,上限总量是 10 个 CPU 和 20GB 的内存 | |
requests.cpu: 10 | |
requests.memory: 10Gi | |
limits.cpu: 10 | |
limits.memory: 20Gi | |
# 只能创建 100 个 PVC 对象,使用 100GB 的持久化存储空间 | |
requests.storage: 100Gi | |
persistentvolumeclaims: 100 | |
# 只能创建 100 个 Pod,100 个 ConfigMap,100 个 Secret,10 个 Service | |
pods: 100 | |
configmaps: 100 | |
secrets: 100 | |
services: 10 | |
# 只能创建 1 个 Job,1 个 CronJob,1 个 Deployment | |
count/jobs.batch: 1 | |
count/cronjobs.batch: 1 | |
count/deployments.apps: 1 |
# 字段解释
CPU 和内存配额,使用
request.*、limits.*,这是和容器资源限制是一样的。存储容量配额,使
requests.storage限制的是 PVC 的存储总量,也可以用persistentvolumeclaims限制 PVC 的个数。核心对象配额,使用对象的名字(英语复数形式),比如
pods、configmaps、secrets、services。其他 API 对象配额,使用
count/name.group的形式,比如count/jobs.batch、count/deployments.apps。
# 使用资源配额
# 部署 quota | |
kubectl apply -f quota-ns.yml | |
# 查看对象 | |
kubectl get quota -n dev-ns | |
# 查看对象(更清晰) | |
kubectl describe quota -n dev-ns |
# LimitRange
- 自动为 Pod 加上资源限制
很小但很有用的辅助对象了 —— LimitRange,简称是 limits,它能为 API 对象添加默认的资源配额限制。
# 样板
apiVersion: v1 | |
kind: LimitRange | |
metadata: | |
name: dev-limits | |
namespace: dev-ns | |
spec: | |
limits: | |
- type: Container | |
defaultRequest: | |
cpu: 200m | |
memory: 50Mi | |
# 每个容器默认申请 0.2 的 CPU 和 50MB 内存 | |
default: | |
cpu: 500m | |
memory: 100Mi | |
# 容器的资源上限是 0.5 的 CPU 和 100MB 内存 | |
- type: Pod | |
max: | |
cpu: 800m | |
memory: 200Mi | |
# 每个 Pod 的最大使用量是 0.8 的 CPU 和 200MB 内存 |
# 字段解释
spec.limits是它的核心属性,描述了默认的资源限制。type是要限制的对象类型,可以是Container、Pod、PersistentVolumeClaim。default是默认的资源上限,对应容器里的resources.limits,只适用于Container。defaultRequest默认申请的资源,对应容器里的resources.requests,同样也只适用于Container。max、min是对象能使用的资源的最大最小值。
# 总结
在生产环境里会有很多用户共同使用 Kubernetes,必然会有对资源的竞争,为了公平起见,避免某些用户过度消耗资源,就非常有必要用名字空间做好集群的资源规划了。
名字空间是一个逻辑概念,没有实体,它的目标是为资源和对象划分出一个逻辑边界,避免冲突。
ResourceQuota 对象可以为名字空间添加资源配额,限制全局的 CPU、内存和 API 对象数量。
LimitRange 对象可以为容器或者 Pod 添加默认的资源配额,简化对象的创建工作。
# 系统监控
# metric-server
# components.yaml | |
apiVersion: v1 | |
kind: ServiceAccount | |
metadata: | |
labels: | |
k8s-app: metrics-server | |
name: metrics-server | |
namespace: kube-system | |
--- | |
apiVersion: rbac.authorization.k8s.io/v1 | |
kind: ClusterRole | |
metadata: | |
labels: | |
k8s-app: metrics-server | |
rbac.authorization.k8s.io/aggregate-to-admin: "true" | |
rbac.authorization.k8s.io/aggregate-to-edit: "true" | |
rbac.authorization.k8s.io/aggregate-to-view: "true" | |
name: system:aggregated-metrics-reader | |
rules: | |
- apiGroups: | |
- metrics.k8s.io | |
resources: | |
- pods | |
- nodes | |
verbs: | |
- get | |
- list | |
- watch | |
--- | |
apiVersion: rbac.authorization.k8s.io/v1 | |
kind: ClusterRole | |
metadata: | |
labels: | |
k8s-app: metrics-server | |
name: system:metrics-server | |
rules: | |
- apiGroups: | |
- "" | |
resources: | |
- nodes/metrics | |
verbs: | |
- get | |
- apiGroups: | |
- "" | |
resources: | |
- pods | |
- nodes | |
verbs: | |
- get | |
- list | |
- watch | |
--- | |
apiVersion: rbac.authorization.k8s.io/v1 | |
kind: RoleBinding | |
metadata: | |
labels: | |
k8s-app: metrics-server | |
name: metrics-server-auth-reader | |
namespace: kube-system | |
roleRef: | |
apiGroup: rbac.authorization.k8s.io | |
kind: Role | |
name: extension-apiserver-authentication-reader | |
subjects: | |
- kind: ServiceAccount | |
name: metrics-server | |
namespace: kube-system | |
--- | |
apiVersion: rbac.authorization.k8s.io/v1 | |
kind: ClusterRoleBinding | |
metadata: | |
labels: | |
k8s-app: metrics-server | |
name: metrics-server:system:auth-delegator | |
roleRef: | |
apiGroup: rbac.authorization.k8s.io | |
kind: ClusterRole | |
name: system:auth-delegator | |
subjects: | |
- kind: ServiceAccount | |
name: metrics-server | |
namespace: kube-system | |
--- | |
apiVersion: rbac.authorization.k8s.io/v1 | |
kind: ClusterRoleBinding | |
metadata: | |
labels: | |
k8s-app: metrics-server | |
name: system:metrics-server | |
roleRef: | |
apiGroup: rbac.authorization.k8s.io | |
kind: ClusterRole | |
name: system:metrics-server | |
subjects: | |
- kind: ServiceAccount | |
name: metrics-server | |
namespace: kube-system | |
--- | |
apiVersion: v1 | |
kind: Service | |
metadata: | |
labels: | |
k8s-app: metrics-server | |
name: metrics-server | |
namespace: kube-system | |
spec: | |
ports: | |
- name: https | |
port: 443 | |
protocol: TCP | |
targetPort: https | |
selector: | |
k8s-app: metrics-server | |
--- | |
apiVersion: apps/v1 | |
kind: Deployment | |
metadata: | |
labels: | |
k8s-app: metrics-server | |
name: metrics-server | |
namespace: kube-system | |
spec: | |
selector: | |
matchLabels: | |
k8s-app: metrics-server | |
strategy: | |
rollingUpdate: | |
maxUnavailable: 0 | |
template: | |
metadata: | |
labels: | |
k8s-app: metrics-server | |
spec: | |
containers: | |
- args: | |
- --cert-dir=/tmp | |
- --secure-port=4443 | |
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname | |
- --kubelet-use-node-status-port | |
- --metric-resolution=15s | |
- --kubelet-insecure-tls # important | |
image: registry.aliyuncs.com/google_containers/metrics-server:v0.6.1 | |
imagePullPolicy: IfNotPresent | |
livenessProbe: | |
failureThreshold: 3 | |
httpGet: | |
path: /livez | |
port: https | |
scheme: HTTPS | |
periodSeconds: 10 | |
name: metrics-server | |
ports: | |
- containerPort: 4443 | |
name: https | |
protocol: TCP | |
readinessProbe: | |
failureThreshold: 3 | |
httpGet: | |
path: /readyz | |
port: https | |
scheme: HTTPS | |
initialDelaySeconds: 20 | |
periodSeconds: 10 | |
resources: | |
requests: | |
cpu: 100m | |
memory: 200Mi | |
securityContext: | |
allowPrivilegeEscalation: false | |
readOnlyRootFilesystem: true | |
runAsNonRoot: true | |
runAsUser: 1000 | |
volumeMounts: | |
- mountPath: /tmp | |
name: tmp-dir | |
nodeSelector: | |
kubernetes.io/os: linux | |
priorityClassName: system-cluster-critical | |
serviceAccountName: metrics-server | |
volumes: | |
- emptyDir: {} | |
name: tmp-dir | |
--- | |
apiVersion: apiregistration.k8s.io/v1 | |
kind: APIService | |
metadata: | |
labels: | |
k8s-app: metrics-server | |
name: v1beta1.metrics.k8s.io | |
spec: | |
group: metrics.k8s.io | |
groupPriorityMinimum: 100 | |
insecureSkipTLSVerify: true | |
service: | |
name: metrics-server | |
namespace: kube-system | |
version: v1beta1 | |
versionPriority: 100 |
# 查看集群里的节点 | |
kubectl top node | |
# 查看 pod 状态 | |
kubectl top pod -n kube-system |
# HorizontalPodAutoscaler
它是专门用来自动伸缩 Pod 数量的对象,适用于 Deployment 和 StatefulSet,但不能用于 DaemonSet 。
HorizontalPodAutoscaler 的能力完全基于 Metrics Server,它从 Metrics Server 获取当前应用的运行指标,主要是 CPU 使用率,再依据预定的策略增加或者减少 Pod 的数量。
1. 首先定义 nginx 的 deploy 和 svc
apiVersion: apps/v1 | |
kind: Deployment | |
metadata: | |
name: ngx-hpa-dep | |
spec: | |
replicas: 1 | |
selector: | |
matchLabels: | |
app: ngx-hpa-dep | |
template: | |
metadata: | |
labels: | |
app: ngx-hpa-dep | |
spec: | |
containers: | |
- image: nginx:alpine | |
name: nginx | |
ports: | |
- containerPort: 80 | |
resources: | |
requests: | |
cpu: 50m | |
memory: 10Mi | |
limits: | |
cpu: 100m | |
memory: 20Mi | |
--- | |
apiVersion: v1 | |
kind: Service | |
metadata: | |
name: ngx-hpa-svc | |
spec: | |
ports: | |
- port: 80 | |
protocol: TCP | |
targetPort: 80 | |
selector: | |
app: ngx-hpa-dep |
注意在它的 spec 里一定要用 resources 字段写清楚资源配额,否则 HorizontalPodAutoscaler 会无法获取 Pod 的指标,也就无法实现自动化扩缩容。
2. 创建 hpa
apiVersion: autoscaling/v1 | |
kind: HorizontalPodAutoscaler | |
metadata: | |
name: ngx-hpa | |
spec: | |
maxReplicas: 10 # Pod 数量的最大值,也就是扩容的上限 | |
minReplicas: 2 # Pod 数量的最小值,也就是缩容的下限 | |
scaleTargetRef: # 以下参数对应上面的 deployment | |
apiVersion: apps/v1 | |
kind: Deployment | |
name: ngx-hpa-dep | |
targetCPUUtilizationPercentage: 5 # CPU 使用率指标,当大于这个值时扩容,小于这个值时缩容 |
# Prometheus
wget https://github.com/prometheus-operator/kube-prometheus/archive/refs/tags/v0.11.0.tar.gz |