# 大模型简介
- LLM:
Large Language Model - 自然语言处理、信息检索、计算机视觉
- 大家应该用的多,比较了解
# 调用大模型 API(百度文心为例)
调用流程文档:https://cloud.baidu.com/doc/WENXINWORKSHOP/s/yloieb01t
- 点击百度智能云千帆控制台,此时需要注册 / 登录,注册后可能需要实名认证。
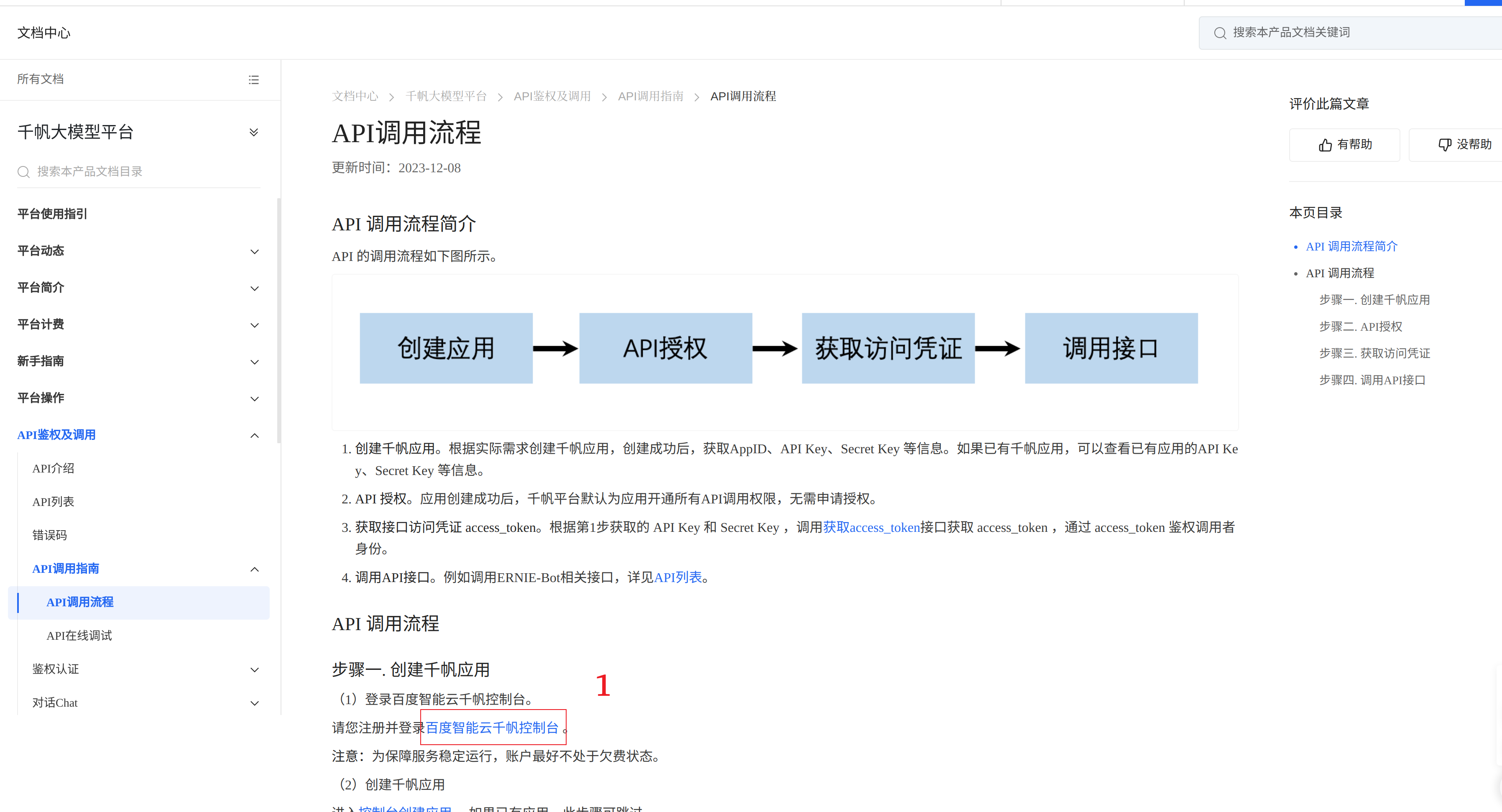
- 点击应用接入,选择创建应用。

- 设置
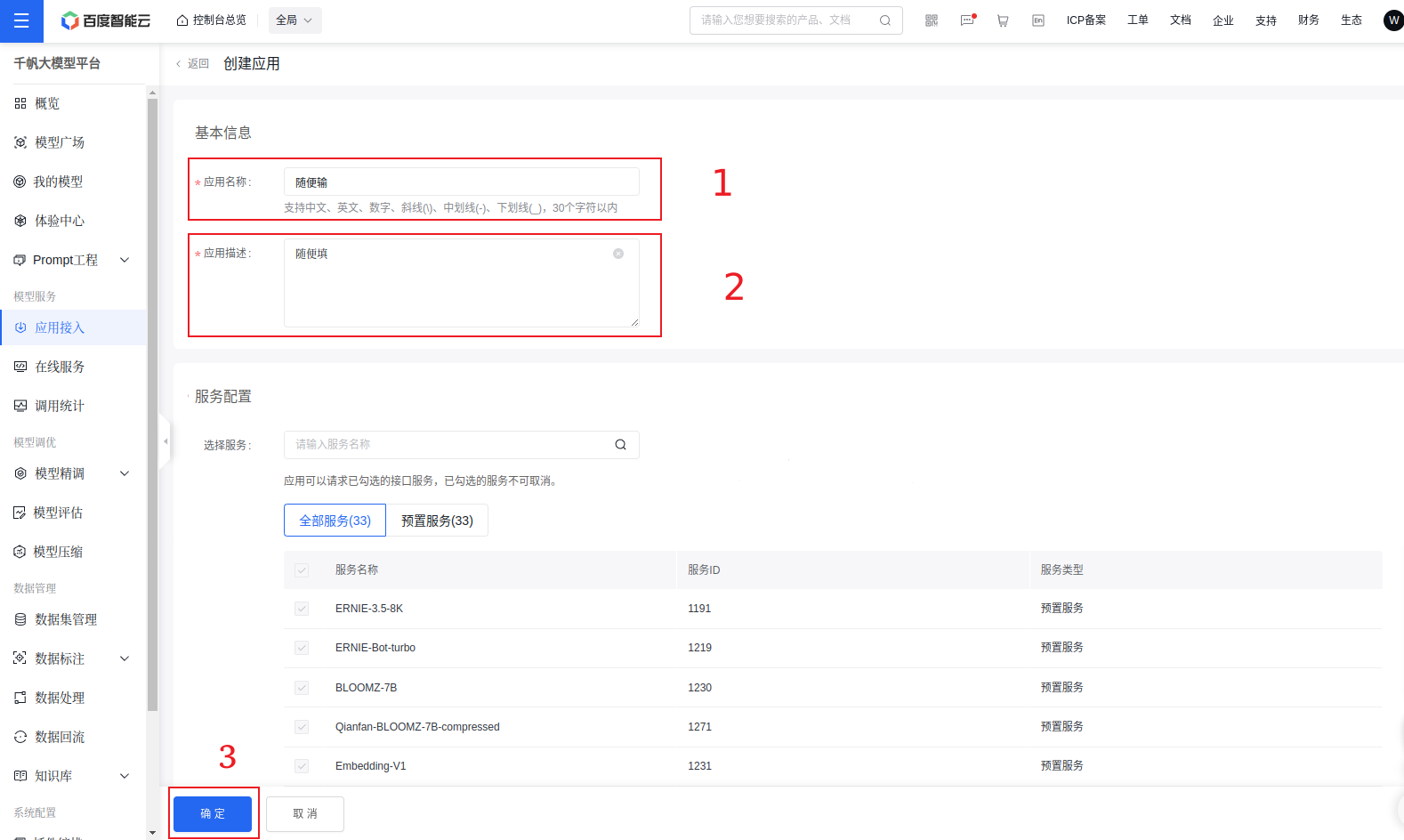
- 保存
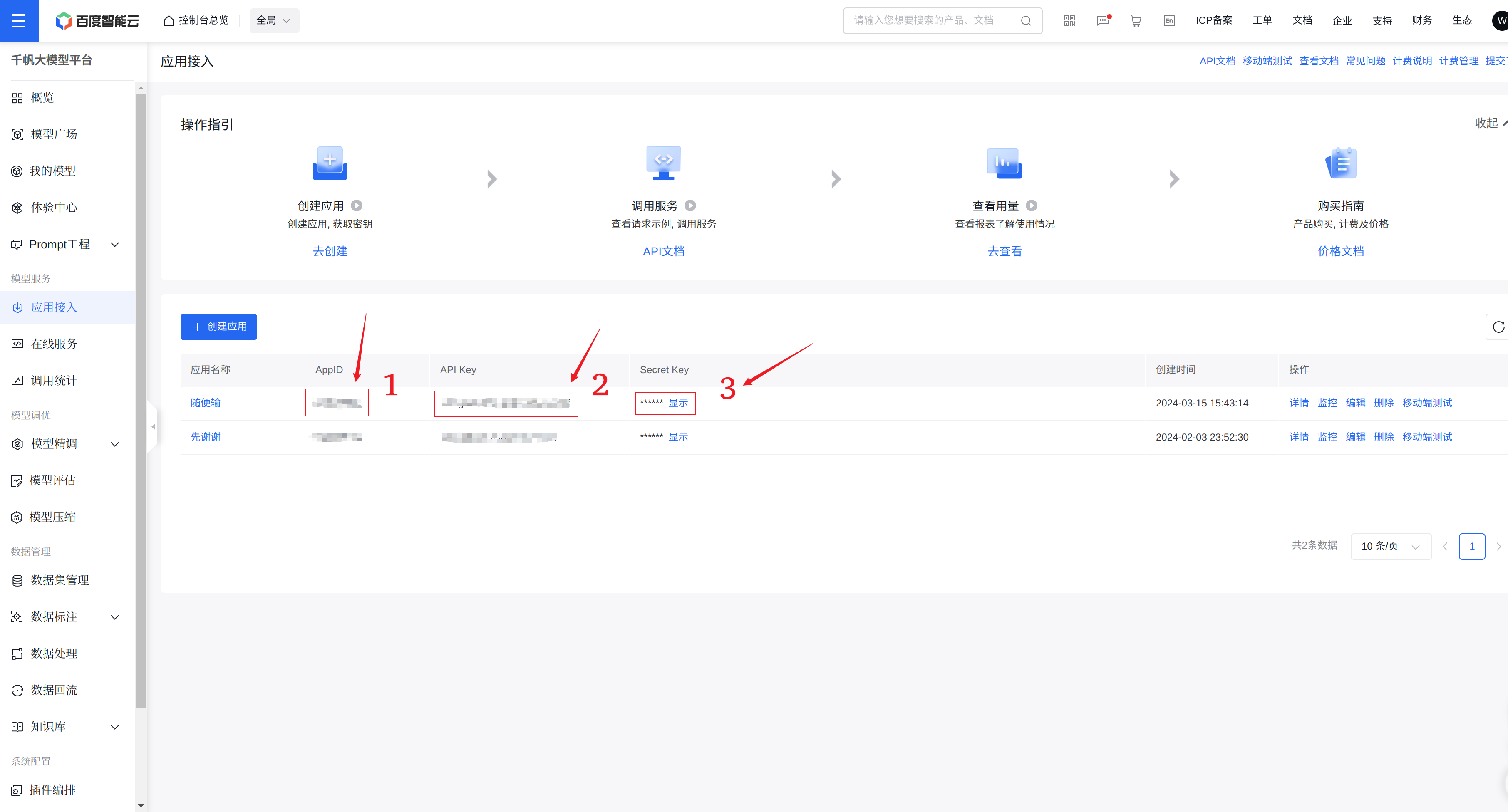
- 发送请求
# 先获取 access_token, 再用 access_token 进行问答 | |
# 把 {api_key} 和 {secret_key} 替换成自己的,需保证网络正常 | |
import requests | |
import json | |
def get_access_token(): | |
""" | |
使用 API Key,Secret Key 获取access_token,替换下列示例中的应用API Key、应用Secret Key | |
""" | |
# 指定网址 | |
url = "https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id={api_key}&client_secret={secret_key}" | |
# 设置 POST 访问 | |
payload = json.dumps("") | |
headers = { | |
'Content-Type': 'application/json', | |
'Accept': 'application/json' | |
} | |
# 通过 POST 访问获取账户对应的 access_token | |
response = requests.request("POST", url, headers=headers, data=payload) | |
return response.json().get("access_token") | |
def get_wenxin(prompt): | |
# 调用接口 | |
url = "https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/eb-instant?access_token={access_token}" | |
# 配置 POST 参数 | |
payload = json.dumps({ | |
"messages": [ | |
{ | |
"role": "user",# user prompt | |
"content": "{}".format(prompt)# 输入的 prompt | |
} | |
] | |
}) | |
headers = { | |
'Content-Type': 'application/json' | |
} | |
# 发起请求 | |
response = requests.request("POST", url, headers=headers, data=payload) | |
# 返回的是一个 Json 字符串 | |
js = json.loads(response.text) | |
print(js["result"]) |
也可以自己试试 OpenAI 的 API 接口调用: https://platform.openai.com/ (自行学习,每个厂家都有自己的调用方法,流程差不多)
因为国内服务器一般不能访问外网,所以大部分时候会使用国内厂家的大模型,自己本地学习的时候可以尝试 OpenAI。
# Langchain 介绍
LangChain 框架是一个开源工具,充分利用了大型语言模型的强大能力,以便开发各种下游应用。它的目标是为各种大型语言模型应用提供通用接口,从而简化应用程序的开发流程。
具体来说,LangChain 框架可以实现数据感知和环境互动,也就是说,它能够让语言模型与其他数据来源连接,并且允许语言模型与其所处的环境进行互动。
LangChain 主要由以下 6 个核心模块组成:
- 模型输入 / 输出(Model I/O):与语言模型交互的接口。
- 数据连接(Data connection):与特定应用程序的数据进行交互的接口。
- 链(Chains):将组件组合实现端到端应用。
- 记忆(Memory):用于链的多次运行之间持久化应用程序状态。
- 代理(Agents):扩展模型的推理能力,用于复杂的应用的调用序列。
- 回调(Callbacks):扩展模型的推理能力,用于复杂的应用的调用序列。
前四个是我们的重点。
# Langchain 核心组件详解
https://datawhalechina.github.io/llm-universe/#/C2/7. langchain 组件详解
# 模型输入 / 输出
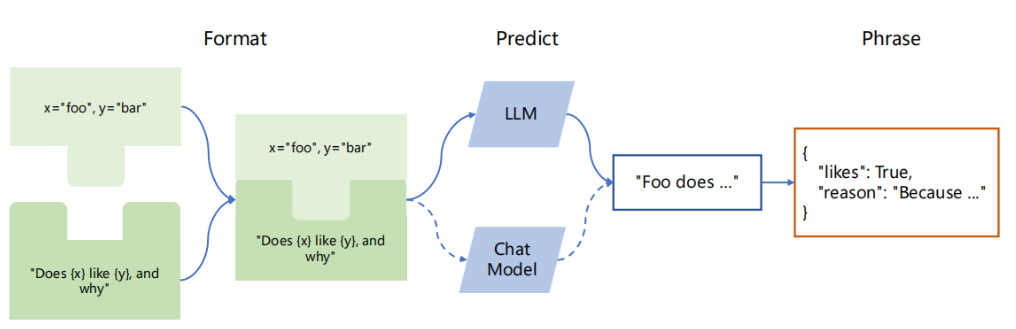
- 可以对输入进行格式化(提前设置好模板,提问时只需输入模板中的变量)
- 可以对输出进行结构化处理(自定义)
# 数据连接
- 可以加入数据集(知识库),让模型检索这些内容后进行作答。
- 数据来源:各种格式文件、网址、(向量)数据库
# 链
- 将多个大型语言模型进行链式组合,或与其他组件进行链式调用
# 记忆
- 上下文
# 代理
- 让大模型借助外部能力
# 回调
函数执行完以后再回头调用你设置好的回调函数
用于日志记录、监视、流式处理(网站上几个字几个字往外冒的输出方式,而不是等到生成完才把结果显示给你)
# 实践
这部分会用到上面申请好的 key,平台可以免费用一些。不涉及大规模文本输入时,key 的价格也十分便宜。
安装一下依赖
pip install langchain |
# 环境变量配置
调用每个大模型的时候都会要求有 api-key 或者类似的密钥,直接写在代码里显然不合适,因为如果你不小心推送到 public 的代码仓库就会被别人有机可乘。
一般在目录下创建一个文件 .env (这时 PyCharm 会提示有相关插件,可以安装一下)
# 删除注释
# 文件格式举例,字符串可以不用加双引号。
# 以下是OPENAI的格式
OPENAI_API_KEY=xxx
OPENAI_BASE_URL=xxx # 非必需,如果你有中转地址,可以填这个
HTTP_PROXY=http://127.0.0.1:7890
HTTPS_PROXY=https://127.0.0.1:7890
# 以下为百度文心的格式
QIANFAN_AK=xxx
QIANFAN_SK=xxx
代码中用这种方式加载:
from dotenv import load_dotenv, find_dotenv | |
_ = load_dotenv(find_dotenv()) | |
# 如果要获取的话 | |
import os | |
import openai | |
os.environ['OPENAI_API_KEY'] | |
# 以下即使不设置,也会自己去环境变量找对应的 | |
openai.api_key = os.environ['OPENAI_API_KEY'] | |
openai.base_url = os.environ['OPENAI_BASE_URL'] |
# 提问
# wenxin_predict.py | |
from langchain_community.chat_models import QianfanChatEndpoint | |
from dotenv import load_dotenv, find_dotenv | |
_ = load_dotenv(find_dotenv()) | |
llm = QianfanChatEndpoint( | |
streaming=False, | |
model="ERNIE-Bot", | |
) | |
res = llm.predict("早上好") | |
print(res) | |
# 早上好!祝您今天一切顺利,心情愉悦,工作顺利,生活美满。如果您有任何问题或需要帮助,请随时告诉我,我将竭诚为您服务。 |
# 链
from dotenv import load_dotenv, find_dotenv | |
from langchain.chains import SimpleSequentialChain, LLMChain | |
from langchain_community.chat_models import QianfanChatEndpoint | |
from langchain_core.prompts import ChatPromptTemplate | |
_ = load_dotenv(find_dotenv()) | |
llm = QianfanChatEndpoint( | |
streaming=False, | |
model="ERNIE-Bot", | |
) | |
# 创建两个子链 | |
# 提示模板 1 :这个提示将接受产品并返回最佳名称来描述该公司 | |
first_prompt = ChatPromptTemplate.from_template( | |
"描述制造{product}的一个公司的最好的名称是什么" | |
) | |
chain_one = LLMChain(llm=llm, prompt=first_prompt) | |
# 提示模板 2 :接受公司名称,然后输出该公司的长为 20 个单词的描述 | |
second_prompt = ChatPromptTemplate.from_template( | |
"写一个20字的描述对于下面这个\ | |
公司:{company_name}的" | |
) | |
chain_two = LLMChain(llm=llm, prompt=second_prompt) | |
# 构建简单顺序链 | |
# 现在我们可以组合两个 LLMChain,以便我们可以在一个步骤中创建公司名称和描述 | |
overall_simple_chain = SimpleSequentialChain(chains=[chain_one, chain_two], verbose=True) | |
# 运行简单顺序链 | |
product = "大号床单套装" | |
overall_simple_chain.run(product) |
# 个性化 Template
from langchain.prompts import ChatPromptTemplate | |
# 这里我们要求模型对给定文本进行中文翻译 | |
template_string = """Translate the text \ | |
that is delimited by triple backticks \ | |
into a Chinese. \ | |
text: ```{text}``` | |
""" | |
# 接着将 Template 实例化 | |
chat_template = ChatPromptTemplate.from_template(template_string) |
# 大模型开发流程
这个部分是一个典型流程,覆盖了一些主要的东西。
目的是让大模型根据已有知识库做出回答,防止大模型针对部分问题推理出错误答案。
# 知识库文档处理
# 文档加载
# PDF 文档
from langchain.document_loaders import PyMuPDFLoader | |
# 创建一个 PyMuPDFLoader Class 实例,输入为待加载的 pdf 文档路径 | |
loader = PyMuPDFLoader("文档路径") | |
# 调用 PyMuPDFLoader Class 的函数 load 对 pdf 文件进行加载 | |
pages = loader.load() | |
print(f"载入后的变量类型为:{type(pages)},", f"该 PDF 一共包含 {len(pages)} 页") | |
page = pages[1] | |
print(f"每一个元素的类型:{type(page)}.", | |
f"该文档的描述性数据:{page.metadata}", | |
f"查看该文档的内容:\n{page.page_content[0:1000]}", | |
sep="\n------\n") |
可以注意一下 Document 的数据结构是怎么构成的,对自定义处理有帮助
# MD 文档
from langchain.document_loaders import UnstructuredMarkdownLoader | |
loader = UnstructuredMarkdownLoader("文档路径") | |
pages = loader.load() | |
print(f"载入后的变量类型为:{type(pages)},", f"该 Markdown 一共包含 {len(pages)} 页") | |
page = pages[0] | |
print(f"每一个元素的类型:{type(page)}.", | |
f"该文档的描述性数据:{page.metadata}", | |
f"查看该文档的内容:\n{page.page_content[0:]}", | |
sep="\n------\n") |
# 文档分割
Langchain 中文本分割器都根据 chunk_size (块大小) 和 chunk_overlap (块与块之间的重叠大小) 进行分割。

- chunk_size 指每个块包含的字符或 Token(如单词、句子等)的数量
- chunk_overlap 指两个块之间共享的字符数量,用于保持上下文的连贯性,避免分割丢失上下文信息
Langchain 提供多种文档分割方式,区别在怎么确定块与块之间的边界、块由哪些字符 /token 组成、以及如何测量块大小
- RecursiveCharacterTextSplitter (): 按字符串分割文本,递归地尝试按不同的分隔符进行分割文本。
- CharacterTextSplitter (): 按字符来分割文本。
- MarkdownHeaderTextSplitter (): 基于指定的标题来分割 markdown 文件。
- TokenTextSplitter (): 按 token 来分割文本。
- SentenceTransformersTokenTextSplitter (): 按 token 来分割文本。
- Language (): 用于 CPP、Python、Ruby、Markdown 等。
- NLTKTextSplitter (): 使用 NLTK(自然语言工具包)按句子分割文本。
- SpacyTextSplitter (): 使用 Spacy 按句子的切割文本。
''' | |
* RecursiveCharacterTextSplitter 递归字符文本分割 | |
RecursiveCharacterTextSplitter 将按不同的字符递归地分割(按照这个优先级["\n\n", "\n", " ", ""]), | |
这样就能尽量把所有和语义相关的内容尽可能长时间地保留在同一位置 | |
RecursiveCharacterTextSplitter需要关注的是4个参数: | |
* separators - 分隔符字符串数组 | |
* chunk_size - 每个文档的字符数量限制 | |
* chunk_overlap - 两份文档重叠区域的长度 | |
* length_function - 长度计算函数 | |
''' | |
#导入文本分割器 | |
from langchain.text_splitter import RecursiveCharacterTextSplitter |
# 知识库中单段文本长度 | |
CHUNK_SIZE = 500 | |
# 知识库中相邻文本重合长度 | |
OVERLAP_SIZE = 50 |
# 此处我们使用 PDF 文件作为示例 | |
from langchain.document_loaders import PyMuPDFLoader | |
# 创建一个 PyMuPDFLoader Class 实例,输入为待加载的 pdf 文档路径 | |
loader = PyMuPDFLoader("../../data_base/knowledge_db/pumkin_book/pumpkin_book.pdf") | |
# 调用 PyMuPDFLoader Class 的函数 load 对 pdf 文件进行加载 | |
pages = loader.load() | |
page = pages[1] | |
# 使用递归字符文本分割器 | |
from langchain.text_splitter import TokenTextSplitter | |
text_splitter = RecursiveCharacterTextSplitter( | |
chunk_size=CHUNK_SIZE, | |
chunk_overlap=OVERLAP_SIZE | |
) | |
text_splitter.split_text(page.page_content[0:1000]) |
split_docs = text_splitter.split_documents(pages) | |
print(f"切分后的文件数量:{len(split_docs)}") | |
print(f"切分后的字符数(可以用来大致评估 token 数):{sum([len(doc.page_content) for doc in split_docs])}") |
# 文档词向量化
Embedding 词嵌入,上学期讲过了,这里使用的是训练好的词嵌入模型,也就是厂家提供的 Embedding 模型。
如果没学过,可以简单理解为用向量对词语进行语义表示。
import numpy as np | |
from dotenv import find_dotenv, load_dotenv | |
from langchain_community.embeddings import QianfanEmbeddingsEndpoint | |
_ = load_dotenv(find_dotenv()) | |
# 定义 Embeddings | |
embedding = QianfanEmbeddingsEndpoint( | |
streaming=True, | |
model="Embedding-V1", | |
chunk_size=16, | |
) | |
query1 = "机器学习" | |
query2 = "强化学习" | |
query3 = "大语言模型" | |
# 通过对应的 embedding 类生成 query 的 embedding。 | |
emb1 = embedding.embed_query(query1) | |
emb2 = embedding.embed_query(query2) | |
emb3 = embedding.embed_query(query3) | |
# 将返回结果转成 numpy 的格式,便于后续计算 | |
emb1 = np.array(emb1) | |
emb2 = np.array(emb2) | |
emb3 = np.array(emb3) | |
print(f"{query1} 生成的为长度 {len(emb1)} 的 embedding , 其前 30 个值为: {emb1[:30]}") |
我们已经生成了对应的向量,我们如何度量文档和问题的相关性呢?
这里提供两种常用的方法:
- 计算两个向量之间的点积。
- 计算两个向量之间的余弦相似度。
print(f"{query1} 和 {query2} 向量之间的点积为:{np.dot(emb1, emb2)}")
print(f"{query1} 和 {query3} 向量之间的点积为:{np.dot(emb1, emb3)}")
print(f"{query2} 和 {query3} 向量之间的点积为:{np.dot(emb2, emb3)}")
余弦相似度计算公式:
print(f"{query1} 和 {query2} 向量之间的余弦相似度为:{cosine_similarity(emb1.reshape(1, -1) , emb2.reshape(1, -1) )}") | |
print(f"{query1} 和 {query3} 向量之间的余弦相似度为:{cosine_similarity(emb1.reshape(1, -1) , emb3.reshape(1, -1) )}") | |
print(f"{query2} 和 {query3} 向量之间的余弦相似度为:{cosine_similarity(emb2.reshape(1, -1) , emb3.reshape(1, -1) )}") |
# 向量数据库使用
选择 Chroma 是因为它轻量级且数据存储在内存中,这使得它非常容易启动和开始使用。
_ = load_dotenv(find_dotenv()) | |
# 加载 PDF | |
loaders_chinese = [ | |
PyMuPDFLoader("path") # 南瓜书 | |
# 大家可以自行加入其他文件 | |
] | |
docs = [] | |
for loader in loaders_chinese: | |
docs.extend(loader.load()) | |
# 切分文档 | |
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=150) | |
split_docs = text_splitter.split_documents(docs) | |
# 定义 Embeddings | |
embedding = QianfanEmbeddingsEndpoint( | |
streaming=True, | |
model="Embedding-V1", | |
chunk_size=16, | |
) |
# 构建 Chroma 向量库
persist_directory = './chroma' | |
vectordb = Chroma.from_documents( | |
documents=split_docs[:100], # 为了速度,只选择了前 100 个切分的 doc 进行生成。 | |
embedding=embedding, | |
persist_directory=persist_directory # 允许我们将 persist_directory 目录保存到磁盘上 | |
) | |
# 保存 | |
vectordb.persist() |
根据持久化文件夹,直接载入一个已有的数据库
# 直接载入 | |
vectordb = Chroma( | |
persist_directory=persist_directory, | |
embedding_function=embedding | |
) | |
print(f"向量库中存储的数量:{vectordb._collection.count()}") |
# 加载
加载多个文件的方式:
import os | |
from langchain.text_splitter import RecursiveCharacterTextSplitter | |
from langchain_community.document_loaders import PyMuPDFLoader, UnstructuredMarkdownLoader | |
from langchain_community.embeddings import QianfanEmbeddingsEndpoint | |
from langchain_community.vectorstores.chroma import Chroma | |
# pdf | |
# 加载 PDF | |
loaders = [ | |
PyMuPDFLoader("path") # 机器学习, | |
] | |
docs = [] | |
for loader in loaders: | |
docs.extend(loader.load()) | |
# md | |
folder_path = "path" | |
files = os.listdir(folder_path) | |
loaders = [] | |
for one_file in files: | |
loader = UnstructuredMarkdownLoader(os.path.join(folder_path, one_file)) | |
loaders.append(loader) | |
for loader in loaders: | |
docs.extend(loader.load()) |
# 检索式问答
from dotenv import load_dotenv, find_dotenv | |
from langchain.chains import RetrievalQA | |
from langchain_community.chat_models import QianfanChatEndpoint | |
from langchain_community.embeddings import QianfanEmbeddingsEndpoint | |
from langchain_community.vectorstores.chroma import Chroma | |
# 声明一个检索式问答链 | |
_ = load_dotenv(find_dotenv()) | |
llm = QianfanChatEndpoint( | |
streaming=False, | |
model="ERNIE-Bot", | |
) | |
embedding = QianfanEmbeddingsEndpoint( | |
streaming=True, | |
model="Embedding-V1", | |
chunk_size=16, | |
) | |
# 假设已经在以下路径持久化 | |
persist_directory = 'path' | |
# 直接载入 | |
vectordb = Chroma( | |
persist_directory=persist_directory, | |
embedding_function=embedding | |
) | |
qa_chain = RetrievalQA.from_chain_type( | |
llm, | |
retriever=vectordb.as_retriever() | |
) | |
# 可以以该方式进行检索问答 | |
question = "本知识库主要包含什么内容" | |
result = qa_chain({"query": question}) | |
print(f"大语言模型的回答为:{result['result']}") |
# 加入 Prompt
from dotenv import load_dotenv, find_dotenv | |
from langchain.chains import RetrievalQA | |
from langchain_community.chat_models import QianfanChatEndpoint | |
from langchain_community.embeddings import QianfanEmbeddingsEndpoint | |
from langchain_community.vectorstores.chroma import Chroma | |
# 声明一个检索式问答链 | |
_ = load_dotenv(find_dotenv()) | |
llm = QianfanChatEndpoint( | |
streaming=False, | |
model="ERNIE-Bot", | |
) | |
embedding = QianfanEmbeddingsEndpoint( | |
streaming=True, | |
model="Embedding-V1", | |
chunk_size=16, | |
) | |
from langchain.prompts import PromptTemplate | |
# Build prompt | |
template = """使用以下上下文片段来回答最后的问题。如果你不知道答案,只需说不知道,不要试图编造答案。答案最多使用三个句子。尽量简明扼要地回答。在回答的最后一定要说"感谢您的提问!" | |
{context} | |
问题:{question} | |
有用的回答:""" | |
QA_CHAIN_PROMPT = PromptTemplate.from_template(template) | |
# 假设已经在以下路径持久化 | |
persist_directory = 'path' | |
# 直接载入 | |
vectordb = Chroma( | |
persist_directory=persist_directory, | |
embedding_function=embedding | |
) | |
# Run chain | |
qa_chain = RetrievalQA.from_chain_type( | |
llm, | |
retriever=vectordb.as_retriever(), | |
return_source_documents=True, | |
chain_type_kwargs={"prompt": QA_CHAIN_PROMPT} | |
) | |
question = " 2025 年大语言模型效果最好的是哪个模型" | |
result = qa_chain({"query": question}) | |
print(f"LLM 对问题的回答:{result['result']}") |
# 记忆功能
有多种数据类型,以下是其中两种
from langchain.memory import ConversationBufferMemory | |
memory = ConversationBufferMemory( | |
memory_key="chat_history", # 与 prompt 的输入变量保持一致。 | |
return_messages=True # 将以消息列表的形式返回聊天记录,而不是单个字符串 | |
) |
from langchain.memory import ChatMessageHistory | |
history = ChatMessageHistory() | |
history.add_user_message("hi!") | |
history.add_ai_message("whats up?") | |
print(history) | |
""" | |
Human: hi! | |
AI: whats up? | |
""" |
# 对话检索链

from langchain.vectorstores import Chroma | |
from dotenv import load_dotenv, find_dotenv | |
import os | |
from langchain_community.chat_models import QianfanChatEndpoint | |
from langchain_community.embeddings import QianfanEmbeddingsEndpoint | |
_ = load_dotenv(find_dotenv()) | |
llm = QianfanChatEndpoint( | |
streaming=False, | |
model="ERNIE-Bot", | |
) | |
embedding = QianfanEmbeddingsEndpoint( | |
streaming=True, | |
model="Embedding-V1", | |
chunk_size=16, | |
) | |
# 向量数据库持久化路径 | |
persist_directory = 'path' | |
# 加载数据库 | |
vectordb = Chroma( | |
persist_directory=persist_directory, # 允许我们将 persist_directory 目录保存到磁盘上 | |
embedding_function=embedding | |
) | |
from langchain.memory import ConversationBufferMemory | |
memory = ConversationBufferMemory( | |
memory_key="chat_history", # 与 prompt 的输入变量保持一致。 | |
return_messages=True # 将以消息列表的形式返回聊天记录,而不是单个字符串 | |
) | |
from langchain.chains import ConversationalRetrievalChain | |
retriever = vectordb.as_retriever() | |
qa = ConversationalRetrievalChain.from_llm( | |
llm, | |
retriever=retriever, | |
memory=memory | |
) | |
question = "我可以学习到关于强化学习的知识吗?" | |
result = qa({"question": question}) | |
print(result['answer']) |